
Last summer I wrote a series of blog posts titled teaching the tidyverse in 2020. As we quickly approach the end of the summer (in the northern hemisphere) and the start of a new academic year, it seems like a good time to provide a new update for teaching the tidyverse, in 2021. The main audience for this post is educators who teach the tidyverse and who might want to bring their teaching materials up to date with updates to the tidyverse that happened over the past year. Much of what is discussed here has already been covered in package update posts on this blog, but my goal is to summarize the highlights that are most relevant to teaching data science with the tidyverse, particularly to new learners.
Specifically, I’ll discuss
- New teaching and learning resources
- Lifecycle stages
- Making reproducible examples with reprex
- Building on the tidyverse for modeling with tidymodels
- Reading data with readr
- Web scraping with rvest
- SQL and data.table translations with dbplyr and dtplyr
Let’s get started!
library(tidyverse)
#> ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──
#> ✔ ggplot2 3.3.5 ✔ purrr 0.3.4
#> ✔ tibble 3.1.4 ✔ dplyr 1.0.7
#> ✔ tidyr 1.1.3 ✔ stringr 1.4.0
#> ✔ readr 2.0.1 ✔ forcats 0.5.1
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()New teaching and learning resources
Before we dive into specific package functionality updates, I’d like to highlight two new teaching and learning resources:
- Cheatsheets: Some of the most popular learning resources for the tidyverse are the cheatsheets, many of which have recently been updated. Huge thanks to our intern Averi Perny on the fantastic work on this project! You can read more about the updates here and find the new cheatsheets here.
- ggplot2 FAQ: A new resource that might be useful for learners is the FAQ we’ve recently developed for ggplot2, which you can access here. These were compiled based on popular questions on StackOverflow and RStudio Community. Each question is accompanied with a short answer as well as an expanded example.
Lifecycle stages
The lifecycle package is used to manage the lifecycle of functions and features within the tidyverse, with clear messaging about what is still experimental and what the tidyverse team is moving away from in the future. But instead of focusing on the package that implements this concept, when teaching, I recommend focusing on the stages of the lifecycle instead. These are experimental, stable, deprecated, and superseded. The lifecycle stages are a useful guide for teaching because they help you see what the tidyverse is moving toward and what it’s moving away from. Being aware of the lifecycle stages (and their associated badges) can be helpful as you review and revise your teaching materials or as you consider incorporating new tooling into your teaching.
The diagram below depicts the lifecycle stages of functions and packages in the tidyverse.
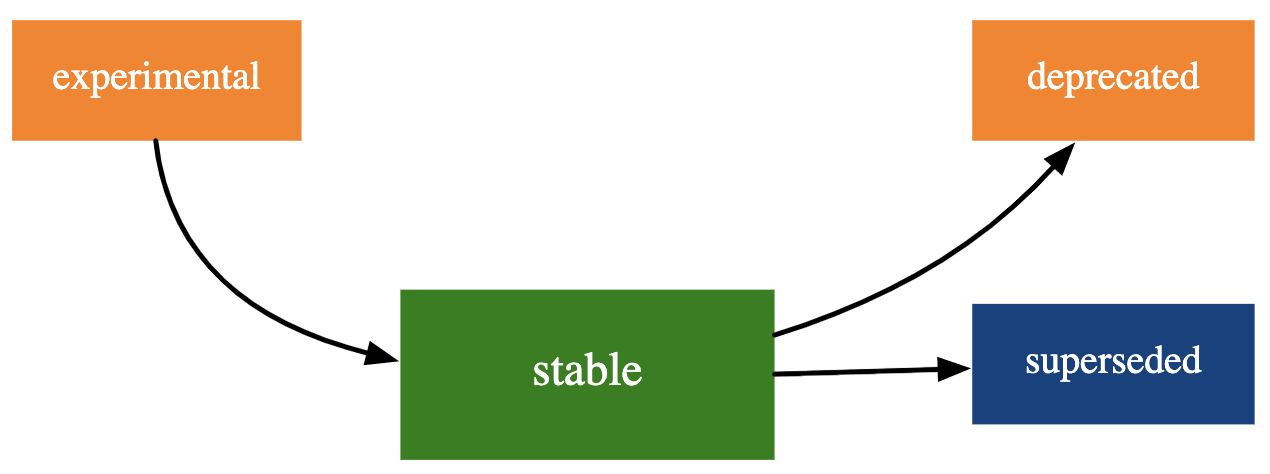
Let’s discuss each of these stages in detail, along with recommendations on how you might consider them in the context of teaching:
 Stable indicates that breaking changes will be avoided where possible, and they’re only made if the long term benefit of such a change exceeds the short term pain of changing existing code. If breaking changes are needed, they will occur gradually. This is the default state for most functions in the tidyverse and hence the badge is generally not shown. Teaching tip: feel free to teach any stable functions, they’re here to stay for the long run!
Stable indicates that breaking changes will be avoided where possible, and they’re only made if the long term benefit of such a change exceeds the short term pain of changing existing code. If breaking changes are needed, they will occur gradually. This is the default state for most functions in the tidyverse and hence the badge is generally not shown. Teaching tip: feel free to teach any stable functions, they’re here to stay for the long run! If a function is noted as deprecated, this means a better alternative is available and this function is scheduled for removal. Generally functions will first be soft deprecated and then deprecated. Very important functions that become deprecated might next be defunct, which means that function continues to exist but the deprecation warning turns into an error. An example of a deprecated function is
If a function is noted as deprecated, this means a better alternative is available and this function is scheduled for removal. Generally functions will first be soft deprecated and then deprecated. Very important functions that become deprecated might next be defunct, which means that function continues to exist but the deprecation warning turns into an error. An example of a deprecated function is
tibble::data_frame(), with the preferred alternativetibble::tibble(). Arguments to functions can also be deprecated, e.g., intidyr::nest()the new argumentnew_colmakes the former.keyargument not needed, and hence.keyis deprecated. You should avoid teaching functions that are deprecated and correct their usage in your students’ code by suggesting the preferred alternative. Superseded indicates that there is a known better alternative for the function, but it’s not going away. Some examples include the following:
Superseded indicates that there is a known better alternative for the function, but it’s not going away. Some examples include the following:tidyr::pivot_longer()/tidyr::pivot_wider()for reshaping data supersedetidyr::spread()/tidyr::gather()(More on these here and here)dplyr::across()for working across columns supersedes scoped verbs such asdplyr::mutate_if(),dplyr::select_at(),dplyr::rename_all(), etc. (More on this here and here)dplyr::slice_sample()withnandproparguments supersedesdplyr::sample_n()/dplyr::sample_frac()(More on this here)
I don’t recommend teaching superseded functions to new learners, and for learners who might be aware of them already, I would recommend discouraging their use (though not correcting, i.e., no point deductions on a formative assessment), and suggesting an alternative.
 Experimental functions are made available so the community can try them out and provide feedback, however they come with no promises for long term stability. For example, the following have been labeled experimental for a while and have received improvements based on community feedback (and are very likely to graduate to stable in the next dplyr release):
Experimental functions are made available so the community can try them out and provide feedback, however they come with no promises for long term stability. For example, the following have been labeled experimental for a while and have received improvements based on community feedback (and are very likely to graduate to stable in the next dplyr release):in
dplyr::summarize():.groupsargument to define the grouping structure of the resultin
dplyr::mutate():.beforeand.afterarguments to control where new columns should appear
I recommend teaching experimental functions with caution, particularly to new learners with whom you might not formally discuss the concept of a “lifecycle”. However there is no reason to discourage use of these functions – if students have stumbled upon a solution that involves an experimental function or argument and has used it correctly on their own, this is likely a good indication that the experiment is working!
If you’d like to learn more about the tidyverse lifecycle, I recommend the following resources:
- Blog post: lifecycle 1.0.0
- Talk: Maintaining the house the tidyverse built by Hadley Wickham at rstudio::global(2021)1
Making reproducible examples with reprex
The reprex package helps users create reproducible examples for posting to GitHub issues, StackOverflow, in Slack messages or snippets, or even to paste into PowerPoint or Keynote slides by placing the code to be shared in your clipboard. I find reprex very useful when teaching because it helps my students provide me with broken code in a way that makes it as easy as possible for me (and for other students in the class) to help them.
There have been many exciting developments in reprex over the year. The one that is perhaps most relevant to teaching are improvements that make it easier to use reprex when working in RStudio Server and RStudio Cloud as well as those that allow using local data when creating a reprex.
Many courses teach R using RStudio Server or RStudio Cloud since this approach circumvents the need for students to install software and allows the instructor to have full control over the R environment their students are learning in. When working in these environments, the R code is running in a web browser and for security reasons it’s not possible for reprex to place code on your system clipboard. When creating a reprex in these environments, you can now simply select the relevant code, and run reprex(). This will create a .md file containing the contents of the reprex, ready for you to copy via Cmd/Ctrl+C.
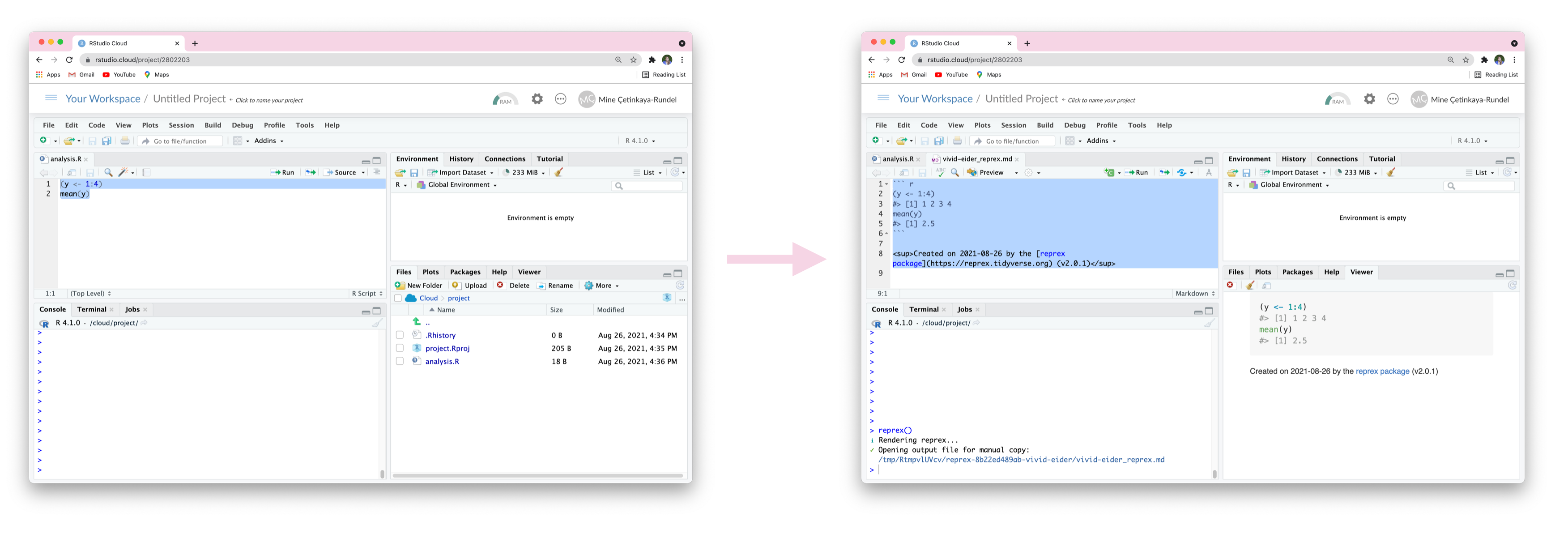
The new wd argument can help students create reprexes when they are working on an assignment involving a local data file. When reprex(wd = "."), the reprex will be executed in the current working directory.2 Writing a reproducible example with a minimal dataset is better practice, but this can be quite difficult for new learners. Being able to easily use local data will make it easier for them to benefit from other aspects of reprex earlier on.
Being able to create a reprex in the current working directory means you can also benefit from a project-level .Rprofile if you happen to have one in your project. This is likely not going to have implications for new learners, for whom this would be an advanced concept, but it can be helpful for instructors who teach with a different suite of packages than what they locally have installed (e.g., CRAN versions for teaching vs. development versions for personal use). If this describes you, I recommend using
renv in projects where you keep teaching materials, which uses .Rprofile to implement a project-specific package library. Then, reprex(wd = ".") will create a reprex using the packages in that library.
For more on updates in reprex, read the blog posts for the 1.0.0 and 2.0.0 releases. And if you’re new to reprex, start here.
Building on tidyverse for modeling with tidymodels
The tidymodels framework is a collection of packages for modeling and machine learning using tidyverse principles. This framework has been around since 2017, but over the past year many of the packages within tidymodels have become stable and gained lots of documentation, making them attractive choices for teaching. If you’re introducing your students to data science with the tidyverse, a great next step to consider is using tidymodels when it comes to modeling and inference.
library(tidymodels)
#> Registered S3 method overwritten by 'tune':
#> method from
#> required_pkgs.model_spec parsnip
#> ── Attaching packages ────────────────────────────────────── tidymodels 0.1.3 ──
#> ✔ broom 0.7.9 ✔ rsample 0.1.0
#> ✔ dials 0.0.9 ✔ tune 0.1.6
#> ✔ infer 1.0.0 ✔ workflows 0.2.3
#> ✔ modeldata 0.1.1 ✔ workflowsets 0.1.0
#> ✔ parsnip 0.1.7 ✔ yardstick 0.0.8
#> ✔ recipes 0.1.16
#> ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
#> ✖ scales::discard() masks purrr::discard()
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ recipes::fixed() masks stringr::fixed()
#> ✖ dplyr::lag() masks stats::lag()
#> ✖ yardstick::spec() masks readr::spec()
#> ✖ recipes::step() masks stats::step()
#> • Use tidymodels_prefer() to resolve common conflicts.From a pedagogical perspective, tidymodels has three main advantages:
- Similar interfaces to different models.
- Model outputs as tibbles, which are straightforward to interact with for learners who already know how to wrangle and visualize data stored in this format.
- Features that help users avoid common machine learning pitfalls such as safeguards in functions that avoid over-fitting by making the test-training split a fundamental part of the modeling process.
Let’s start with the first one — providing similar interfaces to models. Consider the question “How do you define the the number of trees when fitting a random forest model?" The answer is generally "depends on the package: randomForest::randomForest() uses ntree, ranger::ranger() uses num.trees, Spark’s sparklyr::ml_random_forest() uses num_trees". The answer with tidymodels is a bit simpler though: "using the trees argument in the rand_forest() package, regardless of the engine being used to fit the model". This can allow new learners to focus on what"trees" mean and how one decides how many to use, instead of the precise syntax needed by the various packages that can fit random forest models.
The pedagogical advantages of teaching modeling with the full tidymodels framework may not be clear for fitting simple models with
lm(). For example, below we fit a simple linear regression model with a single predictor, using base R first and then using tidymodels.
# base R
lm(hwy ~ cty, data = mpg) %>%
summary()
#>
#> Call:
#> lm(formula = hwy ~ cty, data = mpg)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -5.3408 -1.2790 0.0214 1.0338 4.0461
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.89204 0.46895 1.902 0.0584 .
#> cty 1.33746 0.02697 49.585 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.752 on 232 degrees of freedom
#> Multiple R-squared: 0.9138, Adjusted R-squared: 0.9134
#> F-statistic: 2459 on 1 and 232 DF, p-value: < 2.2e-16
# tidymodels
linear_reg() %>%
set_engine("lm") %>%
fit(hwy ~ cty, data = mpg) %>%
tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 0.892 0.469 1.90 5.84e- 2
#> 2 cty 1.34 0.0270 49.6 1.87e-125The tidymodels approach takes a few more steps, and for a simple model like this, the only advantage is likely in the summarisation step. With tidy(), we get the model output as a tibble, which is more straightforward to interact with programmatically and which, by default, omits the significant stars.
lm(hwy ~ cty, data = mpg) %>%
tidy()
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 0.892 0.469 1.90 5.84e- 2
#> 2 cty 1.34 0.0270 49.6 1.87e-125The pedagogical advantages for the consistent API of the framework become more clear when we move on to fitting different models. Below you can see examples of how we can fit models using various engines or using the same engine, but different modes.
# different engines
linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
logistic_reg() %>%
set_engine("glm") %>%
set_mode("classification")
rand_forest() %>%
set_engine("ranger") %>%
set_mode("regression")
decision_tree() %>%
set_engine("rpart") %>%
set_mode("regression")
# same engine, different modes
svm_linear() %>%
set_engine("LiblineaR") %>%
set_mode("regression")
svm_linear() %>%
set_engine("LiblineaR") %>%
set_mode("classification")Fitting a bunch of models to the same data and picking the one you like the results of the best is not a good approach, so one would rarely see code as it appears in the chunk above in a single R script. Students will encounter these pipelines over the course of a semester, each in a slightly different data context. Because the syntax is uniform, it’s easier to focus on the details of the model, not how to fit the darn thing in R.
Another pedagogical advantage, particularly for teaching tidymodels after tidyverse, is the syntax to build recipes for feature engineering resembles dplyr pipelines for data wrangling. In the following example we first provide a dplyr pipeline for data wrangling, and then show how a similar set of transformations can be achieved using recipes for feature engineering. The example uses the email dataset from the openintro package, which has variables like when the email was sent and received, how many people were cc’ed, number of attachments, etc.
# dplyr for data wrangling
openintro::email %>%
select(-from, -sent_email) %>%
mutate(
day_of_week = lubridate::wday(time), # new variable: day of week
month = lubridate::month(time) # new variable: month
) %>%
select(-time) %>%
mutate(
cc = cut(cc, breaks = c(0, 1)), # discretize cc
attach = cut(attach, breaks = c(0, 1)), # discretize attach
dollar = cut(dollar, breaks = c(0, 1)) # discretize dollar
) %>%
mutate(
inherit = cut(inherit, breaks = c(0, 1, 5, 10, 20)), # discretize inherit
password = cut(password, breaks = c(0, 1, 5, 10, 20)) # discretize password
)
# recipes for data preprocessing and feature engineering
# same steps, similar syntax,
# less bookkeeping for the analyst in modeling setting
recipe(spam ~ ., data = openintro::email) %>%
step_rm(from, sent_email) %>%
step_date(
time,
features = c("dow", "month")
) %>%
step_rm(time) %>%
step_cut(
cc,
attach,
dollar, breaks = c(0, 1)
) %>%
step_cut(
inherit,
password, breaks = c(0, 1, 5, 10, 20)
)You might be thinking “Why do I need the recipes step_*() functions when I can express the same steps with dplyr?” This brings us back to the “features that avoid common machine learning pitfalls”. The advantage of this approach is that once recipe steps are developed with the training data, they can be automatically applied to the testing data for final model assessment.
So far the examples I’ve provided have been in a modeling context, but many statistics and data science courses also teach statistical inference, particularly parameter estimation using confidence intervals and hypothesis testing. The
infer package, which is part of the tidymodels ecosystem, is designed to perform statistical inference using an expressive statistical grammar that cohered with the tidyverse design framework. With recent updates in infer, it is now possible to carry out both theoretical (Central Limit Theorem based) and simulation-based statistical inference using a similar workflow. For example, below we show first the pipeline for building a bootstrap distribution for a mean using a simulation-based approach (with generate() and then calculate() and then we show we define the sampling distribution (with assume()) if we were to build the confidence interval using a theoretical approach.
# simulation-based
set.seed(25)
gss %>%
specify(response = hours) %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "mean")
#> Response: hours (numeric)
#> # A tibble: 1,000 × 2
#> replicate stat
#> <int> <dbl>
#> 1 1 41.8
#> 2 2 41.7
#> 3 3 41.6
#> 4 4 39.3
#> 5 5 41.1
#> 6 6 41.3
#> 7 7 41.0
#> 8 8 43.2
#> 9 9 42.1
#> 10 10 40.4
#> # … with 990 more rows
# theoretical
gss %>%
specify(response = hours) %>%
assume(distribution = "t")
#> A T distribution with 499 degrees of freedom.Other recent updates to infer include support for doing inference for multiple regression as well as behavioral consistency of calculate().
If you’re new to the tidymodels ecosystem, I recommend the following resources for getting started
Expanded documentation:
Book: Tidy Modeling with R by Max Kuhn and Julia Silge
Blog posts:
If you’re new to teaching tidymodels, the following resources can be helpful:
- USCOTS 2021 Breakout session: Tidy up your models (developed and presented with Debbie Yuster)
- Data Science in a Box: Slides, application exercises, computing labs, and homework assignments on modelling and inference with tidymodels.
Reading data with readr
A new version of readr was recently released, with lots of updates outlined in this blog post. The update most relevant to teaching is the new functionality for reading in multiple files at once, or more specifically, reading sets of files with the same columns into one output table in a single command.
Suppose in your data/ folder you have two files, one for sales in August and the other for sales in September. Each of the files contain two variables: brand for brand ID, and n for number of items sold with that brand ID.
files <- fs::dir_ls("data/")
files
#> data/sales-aug.csv
#> data/sales-sep.csvYou can now pass this vector with the paths to multiple files directly to the read_* functions in readr and add an identifying column for which file the records come from.
read_csv(files, id = "path")
#> # A tibble: 7 × 3
#> path brand n
#> <chr> <dbl> <dbl>
#> 1 data/sales-aug… 1234 8
#> 2 data/sales-aug… 8721 2
#> 3 data/sales-aug… 1822 3
#> 4 data/sales-sep… 3333 1
#> 5 data/sales-sep… 2156 3
#> 6 data/sales-sep… 3987 6
#> 7 data/sales-sep… 3216 5Previously this not-so-advanced task required the use of mapping functions from purrr or the vroom package, but now tidyverse users are able to accomplish this task with just readr!
Web scraping with rvest
If you’ve been teaching web scraping with rvest, I recommend updating your teaching materials as you might be able to further simplify and streamline some of the code you present to students. And if you haven’t been teaching web scraping, I recommend reading our paper titled Web Scraping in the Statistics and Data Science Curriculum: Challenges and Opportunities where we discuss how web scraping can be implemented in a pedagogically sound and technically executable way at various levels of statistics and data science curricula.
Most recent updates to rvest include the addition of a new function,
html_text2(), which offers better handling for line breaks. Suppose you have the following paragraph of text across two lines on a webpage.
library(rvest)
#>
#> Attaching package: 'rvest'
#> The following object is masked from 'package:readr':
#>
#> guess_encoding
html <- minimal_html(
"<p>
This is the first sentence in the paragraph.
This is the second sentence that should be on the same line as the first sentence.<br>This third sentence should start on a new line.
</p>"
)With the original
html_text() function extracting the text out of this paragraph results in the following:
html %>% html_text() %>% writeLines()
#>
#> This is the first sentence in the paragraph.
#> This is the second sentence that should be on the same line as the first sentence.This third sentence should start on a new line.
#> Note that the line breaks in the output do not respect the line break defined with <br>.
With the new
html_text2(), <br> is handled appropriately and the line breaks follow the expected pattern.
html %>% html_text2() %>% writeLines()
#> This is the first sentence in the paragraph. This is the second sentence that should be on the same line as the first sentence.
#> This third sentence should start on a new line.The output of
html_text2() is generally what you want, but note that it is slower than
html_text(). This might not make a big difference for teaching web scraping as a new topic, but it is worth keeping in mind when the task involves scraping a large amount of data. Your choice might also depend on what you’re going to do next with the data. For example, if the next step involves tokenizing the scraped text with
tidytext::unnest_tokens() you might not care how the line breaks were handled in the first step.
Since this change involves the addition of a new function without changing behaviour in any existing functions, incorporating it into your teaching would require testing
html_text2() in places where you previously used
html_text() to see if the result is preferable.
Another important update is that
html_node() and
html_nodes() (functions that undoubtedly show up in any lesson on web scraping with rvest) have been superseded in favor of
html_element() and
html_elements(). The motivation behind this update is to better match what learners see when they’re first learning about HTML. When updating teaching materials you should be able to use
html_element() and
html_elements() as drop in replacements for
html_node() and
html_nodes(), respectively.
Finally, if
html_table() didn’t work for you in the past, it’s worth trying again since it’s been rewritten from scratch to more closely match how browsers display tables with merged cells.
For more on updates in rvest, read the rvest 1.0.0. blog post and review the updated rvest vignette.
SQL and data.table translations with dbplyr and dtplyr
Two packages that provide interfaces for translations between dplyr and SQL and
data.table code are dbplyr and dtplyr. If you’re teaching either of these tools alongside the tidyverse, particularly to students who have learned the tidyverse first, the
show_query() function can be very helpful for translating tidyverse code into syntaxes used by these tools.
dtplyr translates dplyr pipelines into equivalent data.table code. To start, we first need to create a
lazy_dt() object which will record the dplyr actions. Then, we write a dplyr pipeline as usual and save the result. The result can be viewed by piping it into
as_tibble() and the data.table code can be viewed with
show_query().
library(dtplyr)
mtcars_dt <- lazy_dt(mtcars)
cyl_summary <- mtcars_dt %>%
group_by(cyl) %>%
summarise(across(disp:wt, mean))
# result
cyl_summary %>% as_tibble()
#> # A tibble: 3 × 5
#> cyl disp hp drat wt
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 4 105. 82.6 4.07 2.29
#> 2 6 183. 122. 3.59 3.12
#> 3 8 353. 209. 3.23 4.00
# query
cyl_summary %>% show_query()
#> `_DT1`[, .(disp = mean(disp), hp = mean(hp), drat = mean(drat),
#> wt = mean(wt)), keyby = .(cyl)]With recent updates, dtplyr can also translate some tidyr functions to data.table, e.g.,
pivot_wider(). In the following example the process is the same: start with
lazy_dt(), write a data transformation step using tidyverse code, view the result with
as_tibble(), and view the query with
show_query().
fish_encounters_dt <- lazy_dt(fish_encounters)
fish_encounters_wider <- fish_encounters_dt %>%
pivot_wider(names_from = station, values_from = seen, values_fill = 0)
# result
fish_encounters_wider %>% as_tibble()
#> # A tibble: 19 × 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE MAW
#> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
#> 1 4842 1 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 0 0 0 0 0 0
#> 5 4847 1 1 1 0 0 0 0 0 0 0 0
#> 6 4848 1 1 1 1 0 0 0 0 0 0 0
#> 7 4849 1 1 0 0 0 0 0 0 0 0 0
#> 8 4850 1 1 0 1 1 1 1 0 0 0 0
#> 9 4851 1 1 0 0 0 0 0 0 0 0 0
#> 10 4854 1 1 0 0 0 0 0 0 0 0 0
#> 11 4855 1 1 1 1 1 0 0 0 0 0 0
#> 12 4857 1 1 1 1 1 1 1 1 1 0 0
#> 13 4858 1 1 1 1 1 1 1 1 1 1 1
#> 14 4859 1 1 1 1 1 0 0 0 0 0 0
#> 15 4861 1 1 1 1 1 1 1 1 1 1 1
#> 16 4862 1 1 1 1 1 1 1 1 1 0 0
#> 17 4863 1 1 0 0 0 0 0 0 0 0 0
#> 18 4864 1 1 0 0 0 0 0 0 0 0 0
#> 19 4865 1 1 1 0 0 0 0 0 0 0 0
# query
fish_encounters_wider %>% show_query()
#> dcast(`_DT2`, formula = fish ~ station, value.var = "seen", fill = 0)Similarly, dbplyr translates dplyr pipelines into equivalent SQL code. The only difference in the following example translating tidyr code to SQL code is the function used in the first step,
memdb_frame(), which creates a database table.
library(dbplyr)
#>
#> Attaching package: 'dbplyr'
#> The following objects are masked from 'package:dplyr':
#>
#> ident, sql
fish_encounters_db <- memdb_frame(fish_encounters)
fish_encounters_wider <- fish_encounters_db %>%
pivot_wider(names_from = station, values_from = seen, values_fill = 0)
# result
fish_encounters_wider %>% as_tibble()
#> # A tibble: 19 × 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE MAW
#> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 4842 1 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 0 0 0 0 0 0
#> 5 4847 1 1 1 0 0 0 0 0 0 0 0
#> 6 4848 1 1 1 1 0 0 0 0 0 0 0
#> 7 4849 1 1 0 0 0 0 0 0 0 0 0
#> 8 4850 1 1 0 1 1 1 1 0 0 0 0
#> 9 4851 1 1 0 0 0 0 0 0 0 0 0
#> 10 4854 1 1 0 0 0 0 0 0 0 0 0
#> 11 4855 1 1 1 1 1 0 0 0 0 0 0
#> 12 4857 1 1 1 1 1 1 1 1 1 0 0
#> 13 4858 1 1 1 1 1 1 1 1 1 1 1
#> 14 4859 1 1 1 1 1 0 0 0 0 0 0
#> 15 4861 1 1 1 1 1 1 1 1 1 1 1
#> 16 4862 1 1 1 1 1 1 1 1 1 0 0
#> 17 4863 1 1 0 0 0 0 0 0 0 0 0
#> 18 4864 1 1 0 0 0 0 0 0 0 0 0
#> 19 4865 1 1 1 0 0 0 0 0 0 0 0
# query
fish_encounters_wider %>% show_query()
#> <SQL>
#> SELECT `fish`, MAX(CASE WHEN (`station` = 'Release') THEN (`seen`) WHEN NOT(`station` = 'Release') THEN (0.0) END) AS `Release`, MAX(CASE WHEN (`station` = 'I80_1') THEN (`seen`) WHEN NOT(`station` = 'I80_1') THEN (0.0) END) AS `I80_1`, MAX(CASE WHEN (`station` = 'Lisbon') THEN (`seen`) WHEN NOT(`station` = 'Lisbon') THEN (0.0) END) AS `Lisbon`, MAX(CASE WHEN (`station` = 'Rstr') THEN (`seen`) WHEN NOT(`station` = 'Rstr') THEN (0.0) END) AS `Rstr`, MAX(CASE WHEN (`station` = 'Base_TD') THEN (`seen`) WHEN NOT(`station` = 'Base_TD') THEN (0.0) END) AS `Base_TD`, MAX(CASE WHEN (`station` = 'BCE') THEN (`seen`) WHEN NOT(`station` = 'BCE') THEN (0.0) END) AS `BCE`, MAX(CASE WHEN (`station` = 'BCW') THEN (`seen`) WHEN NOT(`station` = 'BCW') THEN (0.0) END) AS `BCW`, MAX(CASE WHEN (`station` = 'BCE2') THEN (`seen`) WHEN NOT(`station` = 'BCE2') THEN (0.0) END) AS `BCE2`, MAX(CASE WHEN (`station` = 'BCW2') THEN (`seen`) WHEN NOT(`station` = 'BCW2') THEN (0.0) END) AS `BCW2`, MAX(CASE WHEN (`station` = 'MAE') THEN (`seen`) WHEN NOT(`station` = 'MAE') THEN (0.0) END) AS `MAE`, MAX(CASE WHEN (`station` = 'MAW') THEN (`seen`) WHEN NOT(`station` = 'MAW') THEN (0.0) END) AS `MAW`
#> FROM `dbplyr_001`
#> GROUP BY `fish`I recommend the following resources to get started with these packages: