
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles.
library(tidymodels)
#> ── Attaching packages ────────────────────────────────────── tidymodels 1.0.0 ──
#> ✔ broom 1.0.0 ✔ recipes 1.0.1
#> ✔ dials 1.0.0 ✔ rsample 1.0.0
#> ✔ dplyr 1.0.9 ✔ tibble 3.1.7
#> ✔ ggplot2 3.3.6 ✔ tidyr 1.2.0
#> ✔ infer 1.0.2 ✔ tune 1.0.0
#> ✔ modeldata 1.0.0 ✔ workflows 1.0.0
#> ✔ parsnip 1.0.0 ✔ workflowsets 1.0.0
#> ✔ purrr 0.3.4 ✔ yardstick 1.0.0
#> ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
#> ✖ purrr::discard() masks scales::discard()
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ✖ recipes::step() masks stats::step()
#> • Search for functions across packages at https://www.tidymodels.org/find/Since the beginning of last year, we have been publishing
quarterly updates here on the tidyverse blog summarizing what’s new in the tidymodels ecosystem. The purpose of these regular posts is to share useful new features and any updates you may have missed. You can check out the
tidymodels tag to find all tidymodels blog posts here, including our roundup posts as well as those that are more focused, like these from the past month or so:
Since our last roundup post, there have been CRAN releases of 25 tidymodels packages. You can install these updates from CRAN with:
install.packages(c(
"rsample", "spatialsample", "parsnip", "baguette", "multilevelmod", "discrim",
"plsmod", "poissonreg", "rules", "recipes", "embed", "themis", "textrecipes",
"workflows", "workflowsets", "tune", "yardstick", "broom", "dials", "butcher",
"hardhat", "infer", "stacks", "tidyposterior", "tidypredict"
))- baguette
- broom
- butcher
- dials
- discrim
- embed
- hardhat
- infer
- modeldata
- multilevelmod
- parsnip
- poissonreg
- recipes
- rsample
- rules
- spatialsample
- stacks
- textrecipes
- themis
- tidymodels
- tidyposterior
- tidypredict
- tune
- workflows
- workflowsets
- yardstick
The NEWS files are linked here for each package; you’ll notice that there are a lot! We know it may be bothersome to keep up with all these changes, so we want to draw your attention to our recent blog posts above and also highlight a few more useful updates in today’s blog post.
We are confident that we have created a good foundation with our implementation across many of our packages and we are using this as an opportunity to bump the packages versions to 1.0.0.
Case weights
Much of the work we have been doing so far this year has been related to case weights. For a more detailed account of the deliberations see this earlier post about the use of case weights with tidymodels.
A full worked example can be found in the previous blog post and on the tidymodels site.
As an example let’s go over how case weights are used within tidymodels. We start by simulating a data set using sim_classification(), this data set is going to be unbalanced and we will be using importance weights to give more weight to the minority class. In tidymodels you can use importance_weights() or frequency_weights() to denote what type of weight you are working with. Setting the type of weight should be the first thing you do.
set.seed(1)
training_sim <- sim_classification(5000, intercept = -25) %>%
mutate(
case_wts = ifelse(class == "class_1", 60, 1),
case_wts = importance_weights(case_wts)
)
training_sim %>%
relocate(case_wts, .after = class)
#> # A tibble: 5,000 × 17
#> class case_wts two_factor_1 two_factor_2 non_linear_1 non_linear_2
#> <fct> <imp_wts> <dbl> <dbl> <dbl> <dbl>
#> 1 class_2 1 0.0924 -1.70 -0.579 0.201
#> 2 class_2 1 -0.136 0.608 -0.770 0.114
#> 3 class_2 1 -0.0806 -2.07 -0.709 0.272
#> 4 class_2 1 1.35 2.75 -0.380 0.785
#> 5 class_2 1 -0.238 1.08 -0.700 0.638
#> 6 class_2 1 -0.322 -1.79 0.0534 0.470
#> 7 class_2 1 1.35 -0.102 -0.764 0.827
#> 8 class_2 1 0.595 1.30 -0.0454 0.493
#> 9 class_2 1 0.563 0.916 -0.383 0.775
#> 10 class_2 1 -0.327 -0.457 -0.390 0.704
#> # … with 4,990 more rows, and 11 more variables: non_linear_3 <dbl>,
#> # linear_01 <dbl>, linear_02 <dbl>, linear_03 <dbl>, linear_04 <dbl>,
#> # linear_05 <dbl>, linear_06 <dbl>, linear_07 <dbl>, linear_08 <dbl>,
#> # linear_09 <dbl>, linear_10 <dbl>Now that we have the data we can the resamples we want. We assigned weights before creating the resamples so that information is being carried into the resamples. The weights are not used in the creation of the resamples.
set.seed(2)
sim_folds <- vfold_cv(training_sim, strata = class)When creating the model specification we don’t need to do anything special, as parsnip will apply case weights when there is support for it. If you are unsure if a model supports case weights you can consult the documentation or the show_model_info() function, like so: show_model_info("logistic_reg").
lr_spec <-
logistic_reg(penalty = tune(), mixture = 1) %>%
set_engine("glmnet")Next, we will set up a recipe for preprocessing
sim_rec <-
recipe(class ~ ., data = training_sim) %>%
step_ns(starts_with("non_linear"), deg_free = 10) %>%
step_normalize(all_numeric_predictors())
sim_rec
#> Recipe
#>
#> Inputs:
#>
#> role #variables
#> case_weights 1
#> outcome 1
#> predictor 15
#>
#> Operations:
#>
#> Natural splines on starts_with("non_linear")
#> Centering and scaling for all_numeric_predictors()The recipe automatically detects the case weights even though they are captured by the dot on the right-hand side of the formula. The recipe automatically sets its role and will error if that column is changed in any way.
As mentioned above, any unsupervised steps are unaffected by importance weights so neither step_ns() or step_normalize() use the weights in their calculations.
When using case weights, we would like to encourage users to keep their model and preprocessing tool within a workflow. The workflows package now has an add_case_weights() function to help here:
lr_wflow <-
workflow() %>%
add_model(lr_spec) %>%
add_recipe(sim_rec) %>%
add_case_weights(case_wts)
lr_wflow
#> ══ Workflow ════════════════════════════════════════════════════════════════════
#> Preprocessor: Recipe
#> Model: logistic_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> 2 Recipe Steps
#>
#> • step_ns()
#> • step_normalize()
#>
#> ── Case Weights ────────────────────────────────────────────────────────────────
#> case_wts
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> Logistic Regression Model Specification (classification)
#>
#> Main Arguments:
#> penalty = tune()
#> mixture = 1
#>
#> Computational engine: glmnetAnd that is all you need to use case weights, the remaining functions from the tune and yardstick package know how to deal with case weights depending on the type of weight.
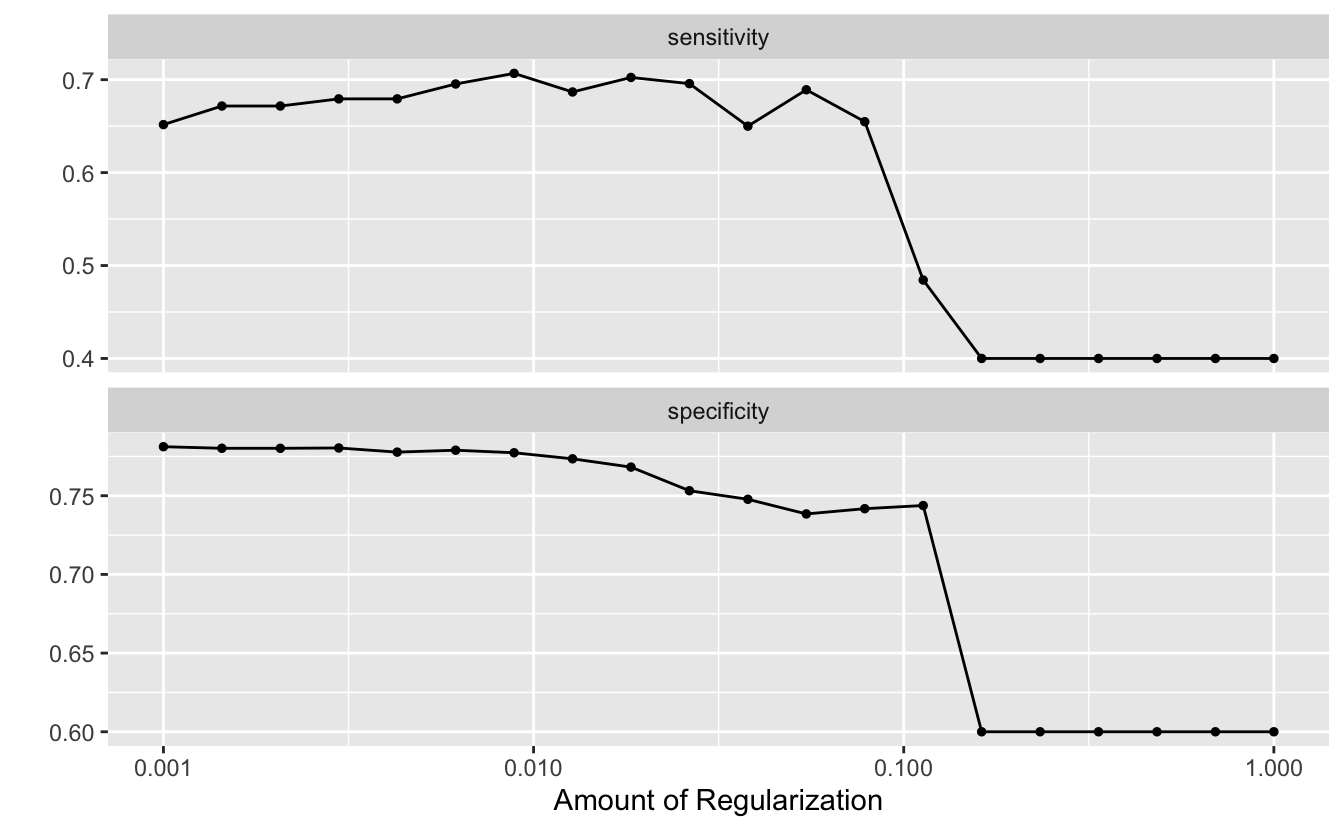
cls_metrics <- metric_set(sensitivity, specificity)
grid <- tibble(penalty = 10^seq(-3, 0, length.out = 20))
set.seed(3)
lr_res <-
lr_wflow %>%
tune_grid(resamples = sim_folds, grid = grid, metrics = cls_metrics)
autoplot(lr_res)
Non-standard roles in recipes
The recipes package use the idea of roles to determine how and when the different variables are used. The main roles are "outcome", "predictor", and now "case_weights". You are also able to change the roles of these variables using add_role() and update_role().
With a recent addition of case weights as another type of standard role, we have made recipes more robust. It now checks that all columns in the data supplied to recipe() are also present in the new_data supplied to bake(). An exception is made for columns with roles of either "outcome" or "case_weights" because these are typically not required at bake() time.
This change for stricter checking of roles will mean that you might need to make some small changes to your code if you are using non-standard roles.
Let’s look at the tate_text data set as an example:
data("tate_text")
glimpse(tate_text)
#> Rows: 4,284
#> Columns: 5
#> $ id <dbl> 21926, 20472, 20474, 20473, 20513, 21389, 121187, 19455, 20938,…
#> $ artist <fct> "Absalon", "Auerbach, Frank", "Auerbach, Frank", "Auerbach, Fra…
#> $ title <chr> "Proposals for a Habitat", "Michael", "Geoffrey", "Jake", "To t…
#> $ medium <fct> "Video, monitor or projection, colour and sound (stereo)", "Etc…
#> $ year <dbl> 1990, 1990, 1990, 1990, 1990, 1990, 1990, 1990, 1990, 1990, 199…This data set includes an id variable that shouldn’t have any predictive power and a title variable that we want to ignore for now. We can let the recipe know that we don’t want it to treat id and title as predictors by giving them a different role which we will call "id" here:
tate_rec <- recipe(year ~ ., data = tate_text) %>%
update_role(id, title, new_role = "id") %>%
step_dummy_extract(artist, medium, sep = ", ")
tate_rec_prepped <- prep(tate_rec)This will now error when we try to apply the recipe to new data that contains only our predictors:
new_painting <- tibble(
artist = "Hamilton, Richard",
medium = "Letterpress on paper"
)
bake(tate_rec_prepped, new_painting)
#> Error in `bake()`:
#> ! The following required columns are missing from `new_data`: "id", "title".
#> ℹ These columns have one of the following roles, which are required at `bake()` time: "id".
#> ℹ If these roles are not required at `bake()` time, use `update_role_requirements(role = "your_role", bake = FALSE)`.It complains because the recipe is expecting the id and title variables to be in the data set passed to bake(). We can use
update_role_requirements() to tell the recipe that variables of role "id" are not required when baking and we are good to go!
tate_rec <- recipe(year ~ ., data = tate_text) %>%
update_role(id, title, new_role = "id") %>%
update_role_requirements(role = "id", bake = FALSE) %>%
step_dummy_extract(artist, medium, sep = ", ")
tate_rec_prepped <- prep(tate_rec)
bake(tate_rec_prepped, new_painting)
#> # A tibble: 1 × 2,675
#> artist_Abigail artist_Abraham artist_Absalon artist_Abts artist_Achill
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 0 0 0 0
#> # … with 2,670 more variables: artist_Ackroyd <dbl>, artist_Adam <dbl>,
#> # artist_Agnes <dbl>, artist_Ahtila <dbl>, artist_Ai <dbl>,
#> # artist_Akram <dbl>, artist_Aksel <dbl>, artist_Al <dbl>,
#> # artist_Al.Ani <dbl>, artist_Alan <dbl>, artist_Albert <dbl>,
#> # artist_Aleksandra <dbl>, artist_Alex <dbl>, artist_Alexander <dbl>,
#> # artist_Alexandre.da <dbl>, artist_Alfredo <dbl>, artist_Alice <dbl>,
#> # artist_Alimpiev <dbl>, artist_Alison <dbl>, artist_Allen <dbl>, …Acknowledgements
applicable @EmilHvitfeldt, @marlycormar, @mikemahoney218, and @topepo.
baguette: @juliasilge, and @topepo.
bonsai: @bwilkowski, @joeycouse, @pinogl, @simonpcouch, and @topepo.
broom: @behrman, @corybrunson, @fschaffner, @gjones1219, @grantmcdermott, @mfansler, @michaeltopper1, @ray-p144, @RichardJActon, @russHyde, @simonpcouch, @tappek, @Timelessprod, and @vincentarelbundock.
butcher: @cregouby, @davidkane9, @DavisVaughan, @juliasilge, and @simonpcouch.
censored: @bcjaeger, @brunocarlin, @erikvona, @gvelasq, @hfrick, @mikemahoney218, and @topepo.
corrr: @astamm, @EmilHvitfeldt, @john-s-f, @juliasilge, and @thisisdaryn.
dials: @DavisVaughan, @EmilHvitfeldt, @franzbischoff, @hadley, @hfrick, @mikemahoney218, @py9mrg, @simonpcouch, and @topepo.
discrim: @EmilHvitfeldt, @hfrick, @jmarshallnz, @juliasilge, and @topepo.
embed: @EmilHvitfeldt, @exsell-jc, @juliasilge, @mkhansa, @talegari, and @topepo.
hardhat: @DavisVaughan, @jonthegeek, @mdancho84, and @topepo.
infer: @gdbassett, @liubao210, @nipnipj, and @simonpcouch.
modeldata: @EmilHvitfeldt, @jbkunst, @juliasilge, @simonpcouch, and @topepo.
multilevelmod: @a-difabio, @EmilHvitfeldt, @hfrick, @sitendug, @topepo, and @YiweiZhu.
parsnip: @bappa10085, @brunocarlin, @cb12991, @DavisVaughan, @deschen1, @edgararuiz, @EmilHvitfeldt, @emmamendelsohn, @exsell-jc, @fdeoliveirag, @gundalav, @hfrick, @jmarshallnz, @joeycouse, @juliasilge, @Npaffen, @oj713, @pmags, @PursuitOfDataScience, @qiushiyan, @salim-b, @shosaco, @simonpcouch, @tolliam, and @topepo.
plsmod: @juliasilge.
poissonreg: @hfrick, @juliasilge, and @topepo.
recipes: @abichat, @albertiniufu, @AndrewKostandy, @aridf, @brunocarlin, @cb12991, @conorjudge, @DavisVaughan, @duccioa, @edgararuiz, @EmilHvitfeldt, @exsell-jc, @gundalav, @hsbadr, @jkennel, @joeycouse, @joranE, @juliasilge, @kendonB, @krzjoa, @madprogramer, @mdporter, @mdsteiner, @nipnipj, @PursuitOfDataScience, @r2evans, @simonpcouch, @szymonkusak, @themichjam, @tmastny, @tomazweiss, @topepo, @TylerGrantSmith, and @zenggyu.
rsample: @DavisVaughan, @dfalbel, @juliasilge, @mattwarkentin, @mdporter, @mikemahoney218, @pgoodling-usgs, @sametsoekel, @topepo, and @wkdavis.
rules: @DesmondChoy, @EmilHvitfeldt, @juliasilge, @simonpcouch, @topepo, and @wdkeyzer.
shinymodels: @juliasilge, and @simonpcouch.
spatialsample: @juliasilge, @mikemahoney218, @MxNl, @nipnipj, and @PathosEthosLogos.
stacks: @amcmahon17, @domijan, @Jeffrothschild, @mcavs, @mvt-oviedo, @osorensen, @py9mrg, @rcannood, @Saarialho, @simonpcouch, and @williamshell.
textrecipes: @EmilHvitfeldt, @NLDataScientist, @PursuitOfDataScience, and @raj-hubber.
themis: @coforfe, and @EmilHvitfeldt.
tidymodels: @DavisVaughan, @EngrStudent, @exsell-jc, @juliasilge, @kcarnold, @scottlyden, and @topepo.
tidyposterior: @jmgirard, @juliasilge, @mikemahoney218, @mone27, and @topepo.
tidypredict: @juliasilge, @mgirlich, @simonpcouch, and @topepo.
tune: @DavisVaughan, @dax44, @EmilHvitfeldt, @felxcon, @franzbischoff, @hfrick, @joeycouse, @juliasilge, @mattwarkentin, @mdancho84, @mikemahoney218, @munoztd0, @nikhilpathiyil, @pgoodling-usgs, @py9mrg, @qiushiyan, @siegfried, @simonpcouch, @thegargiulian, @topepo, @williamshell, and @wtbxsjy.
usemodels: @aloes2512, @amcmahon17, @juliasilge, and @larry77.
workflows: @CarstenLange, @dajmcdon, @DavisVaughan, @EmilHvitfeldt, @hfrick, @juliasilge, @nipnipj, @simonpcouch, @themichjam, and @TylerGrantSmith.
workflowsets: @a-difabio, @BorisDelange, @DavisVaughan, @hfrick, @juliasilge, @simonpcouch, @topepo, @wdefreitas, and @yonicd.
yardstick: @1lliter8, @amcmahon17, @brshallo, @DavisVaughan, @gsverhoeven, @mikemahoney218, @parsifal9, and @sametsoekel.