
We’re super stoked to announce the first release of the bonsai package on CRAN! bonsai is a parsnip extension package for tree-based models.
You can install it from CRAN with:
install.packages("bonsai")Without extension packages, the parsnip package already supports fitting decision trees, random forests, and boosted trees. The bonsai package introduces support for two additional engines that implement variants of these algorithms:
- partykit: conditional inference trees via
decision_tree()and conditional random forests viarand_forest() - LightGBM: optimized gradient boosted trees via
boost_tree()
As we introduce further support for tree-based model engines in the tidymodels, new implementations will reside in this package (rather than parsnip).
To demonstrate how to use the package, we’ll fit a few tree-based models and explore their output. First, loading bonsai as well as the rest of the tidymodels core packages:
library(bonsai)
#> Loading required package: parsnip
library(tidymodels)
#> ── Attaching packages ────────────────────────────────────── tidymodels 0.2.0 ──
#> ✔ broom 0.8.0 ✔ rsample 0.1.1
#> ✔ dials 1.0.0 ✔ tibble 3.1.7
#> ✔ dplyr 1.0.9 ✔ tidyr 1.2.0
#> ✔ ggplot2 3.3.6 ✔ tune 0.2.0
#> ✔ infer 1.0.2 ✔ workflows 0.2.6
#> ✔ modeldata 0.1.1.9000 ✔ workflowsets 0.2.1
#> ✔ purrr 0.3.4 ✔ yardstick 1.0.0
#> ✔ recipes 0.2.0
#> ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
#> ✖ purrr::discard() masks scales::discard()
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ✖ recipes::step() masks stats::step()
#> • Dig deeper into tidy modeling with R at https://www.tmwr.orgNote that we use a development version of the
modeldata package to generate example data later on in this post using the new sim_regression() function—you can install this version of the package using pak::pak(tidymodels/modeldata).
We’ll use a dataset containing measurements on 3 different species of penguins as an example. Loading that data in and checking it out:
data(penguins, package = "modeldata")
str(penguins)
#> tibble [344 × 7] (S3: tbl_df/tbl/data.frame)
#> $ species : Factor w/ 3 levels "Adelie","Chinstrap",..: 1 1 1 1 1 1 1 1 1 1 ...
#> $ island : Factor w/ 3 levels "Biscoe","Dream",..: 3 3 3 3 3 3 3 3 3 3 ...
#> $ bill_length_mm : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
#> $ bill_depth_mm : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
#> $ flipper_length_mm: int [1:344] 181 186 195 NA 193 190 181 195 193 190 ...
#> $ body_mass_g : int [1:344] 3750 3800 3250 NA 3450 3650 3625 4675 3475 4250 ...
#> $ sex : Factor w/ 2 levels "female","male": 2 1 1 NA 1 2 1 2 NA NA ...Specifically, we’ll make use of flipper length and home island to model a penguin’s species:
ggplot(penguins) +
aes(x = island, y = flipper_length_mm, col = species) +
geom_jitter(width = .2)
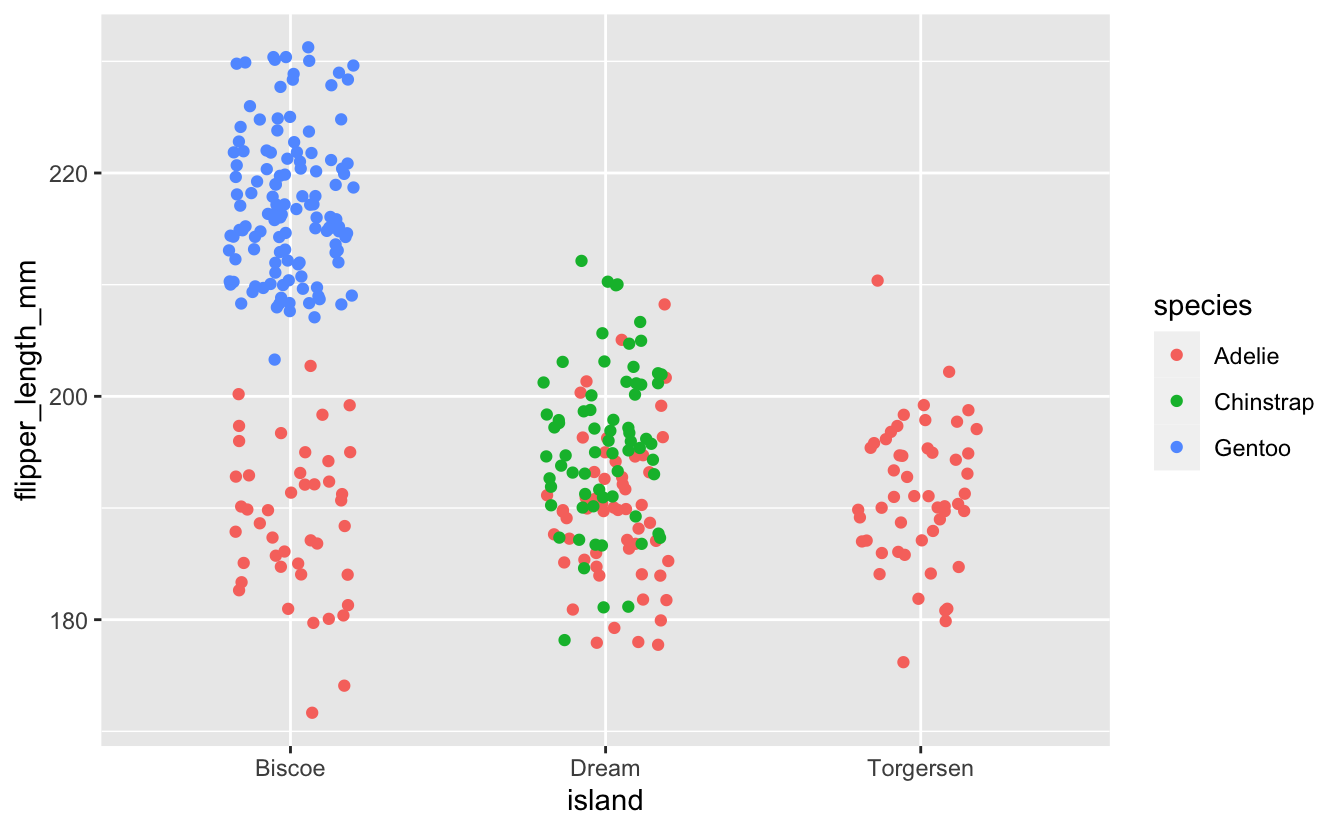
Looking at this plot, you might begin to imagine your own simple set of binary splits for guessing which species a penguin might be given its home island and flipper length. Given that this small set of predictors almost completely separates our outcome with only a few splits, a relatively simple tree should serve our purposes just fine.
Decision Trees
bonsai introduces support for fitting decision trees with partykit, which implements a variety of decision trees called conditional inference trees (CITs).
CITs differ from implementations of decision trees available elsewhere in the tidymodels in the criteria used to generate splits. The details of how these criteria differ are outside of the scope of this post.1 Practically, though, CITs offer a few notable advantages over CART- and C5.0-based decision trees:
- Overfitting: Common implementations of decision trees are notoriously prone to overfitting, and require several well-chosen penalization (i.e. cost-complexity) and early stopping (e.g. pruning, max depth) hyperparameters to fit a model that will perform well when predicting on new observations. “Out-of-the-box,” CITs are not as prone to these same issues and do not accept a penalization parameter at all.
- Selection bias: Common implementations of decision trees are biased towards selecting variables with many possible split points or missing values. CITs are natively not prone to the first issue, and many popular implementations address the second vulnerability.
To define a conditional inference tree model specification, just set the modeling engine to "partykit" when creating a decision tree. Fitting to the penguins data, then:
dt_mod <-
decision_tree() %>%
set_engine(engine = "partykit") %>%
set_mode(mode = "classification") %>%
fit(
formula = species ~ flipper_length_mm + island,
data = penguins
)
dt_mod
#> parsnip model object
#>
#>
#> Model formula:
#> species ~ flipper_length_mm + island
#>
#> Fitted party:
#> [1] root
#> | [2] island in Biscoe
#> | | [3] flipper_length_mm <= 203
#> | | | [4] flipper_length_mm <= 196: Adelie (n = 38, err = 0.0%)
#> | | | [5] flipper_length_mm > 196: Adelie (n = 8, err = 25.0%)
#> | | [6] flipper_length_mm > 203: Gentoo (n = 122, err = 0.0%)
#> | [7] island in Dream, Torgersen
#> | | [8] island in Dream
#> | | | [9] flipper_length_mm <= 192: Adelie (n = 59, err = 33.9%)
#> | | | [10] flipper_length_mm > 192: Chinstrap (n = 65, err = 26.2%)
#> | | [11] island in Torgersen: Adelie (n = 52, err = 0.0%)
#>
#> Number of inner nodes: 5
#> Number of terminal nodes: 6Do any of these splits line up with your intuition? This tree results in only 6 terminal nodes and describes the structure shown in the above plot quite well.
Read more about this implementation of decision trees in
?details_decision_tree_partykit.
Random Forests
One generalization of a decision tree is a random forest, which fits a large number of decision trees, each independently of the others. The fitted random forest model combines predictions from the individual decision trees to generate its predictions.
bonsai introduces support for random forests using the partykit engine, which implements an algorithm called a conditional random forest. Conditional random forests are a type of random forest that uses conditional inference trees (like the one we fit above!) for its constituent decision trees.
To fit a conditional random forest with partykit, our code looks pretty similar to that which we we needed to fit a conditional inference tree. Just switch out
decision_tree() with
rand_forest() and remember to keep the engine set as "partykit":
rf_mod <-
rand_forest() %>%
set_engine(engine = "partykit") %>%
set_mode(mode = "classification") %>%
fit(
formula = species ~ flipper_length_mm + island,
data = penguins
)Read more about this implementation of random forests in
?details_rand_forest_partykit.
Boosted Trees
Another generalization of a decision tree is a series of decision trees where each tree depends on the results of previous trees—this is called a boosted tree. bonsai implements an additional parsnip engine for this model type called "lightgbm". While fitting boosted trees is quite computationally intensive, especially with high-dimensional data, LightGBM provides an implementation of a highly efficient variant of the algorithm.
To make use of it, start out with a boost_tree model spec and set engine = "lightgbm":
bt_mod <-
boost_tree() %>%
set_engine(engine = "lightgbm") %>%
set_mode(mode = "classification") %>%
fit(
formula = species ~ flipper_length_mm + island,
data = penguins
)The main benefit of using LightGBM is its computational efficiency: as the number of observations in training data increases, we can observe an increasingly substantial decrease in time-to-fit when using the LightGBM engine as compared to other implementations of boosted trees, like XGBoost.
To show this, we’ll use the sim_regression() function from modeldata to simulate increasingly large datasets that we can fit models to. For example, generating a dataset with 10 observations and 20 numeric predictors:
sim_regression(num_samples = 10)
#> # A tibble: 10 × 21
#> outcome predictor_01 predictor_02 predictor_03 predictor_04 predictor_05
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 41.9 -3.15 3.72 -0.800 -5.87 0.265
#> 2 49.4 4.93 6.15 5.09 0.501 -2.45
#> 3 -9.20 0.0200 -2.31 4.64 0.422 3.14
#> 4 -0.385 -1.97 -2.56 -0.0182 1.83 -4.23
#> 5 8.08 -0.266 -0.574 -1.08 -1.75 1.57
#> 6 3.79 0.145 3.86 3.91 3.32 -4.27
#> 7 1.12 -6.35 -2.39 0.119 0.848 1.74
#> 8 3.21 4.56 3.20 -2.68 -1.11 0.729
#> 9 -4.56 2.97 -1.36 -1.90 -1.01 0.557
#> 10 0.140 -0.234 -1.05 0.551 0.861 -0.937
#> # … with 15 more variables: predictor_06 <dbl>, predictor_07 <dbl>,
#> # predictor_08 <dbl>, predictor_09 <dbl>, predictor_10 <dbl>,
#> # predictor_11 <dbl>, predictor_12 <dbl>, predictor_13 <dbl>,
#> # predictor_14 <dbl>, predictor_15 <dbl>, predictor_16 <dbl>,
#> # predictor_17 <dbl>, predictor_18 <dbl>, predictor_19 <dbl>,
#> # predictor_20 <dbl>Now, fitting boosted trees on increasingly large datasets with XGBoost and LightGBM and observing time-to-fit:
# given an engine and nrow(training_data), return the time to fit
time_boost_fit <- function(engine, n) {
time <-
system.time({
boost_tree() %>%
set_engine(engine = engine) %>%
set_mode(mode = "regression") %>%
fit(
formula = outcome ~ .,
data = sim_regression(num_samples = n)
)
})
tibble(
engine = engine,
n = n,
time_to_fit = time[["elapsed"]]
)
}
# setup engine and n_samples combinations
engines <- rep(c(XGBoost = "xgboost", LightGBM = "lightgbm"), each = 11)
n_samples <- round(rep(10 * 10^(seq(2, 4.5, .25)), times = 2))
# apply the function over each combination
fit_times <-
map2_dfr(
engines,
n_samples,
time_boost_fit
) %>%
mutate(
engine = factor(engine, levels = c("xgboost", "lightgbm"))
)
# visualize results
ggplot(fit_times) +
aes(x = n, y = time_to_fit, col = engine) +
geom_line() +
scale_x_log10()
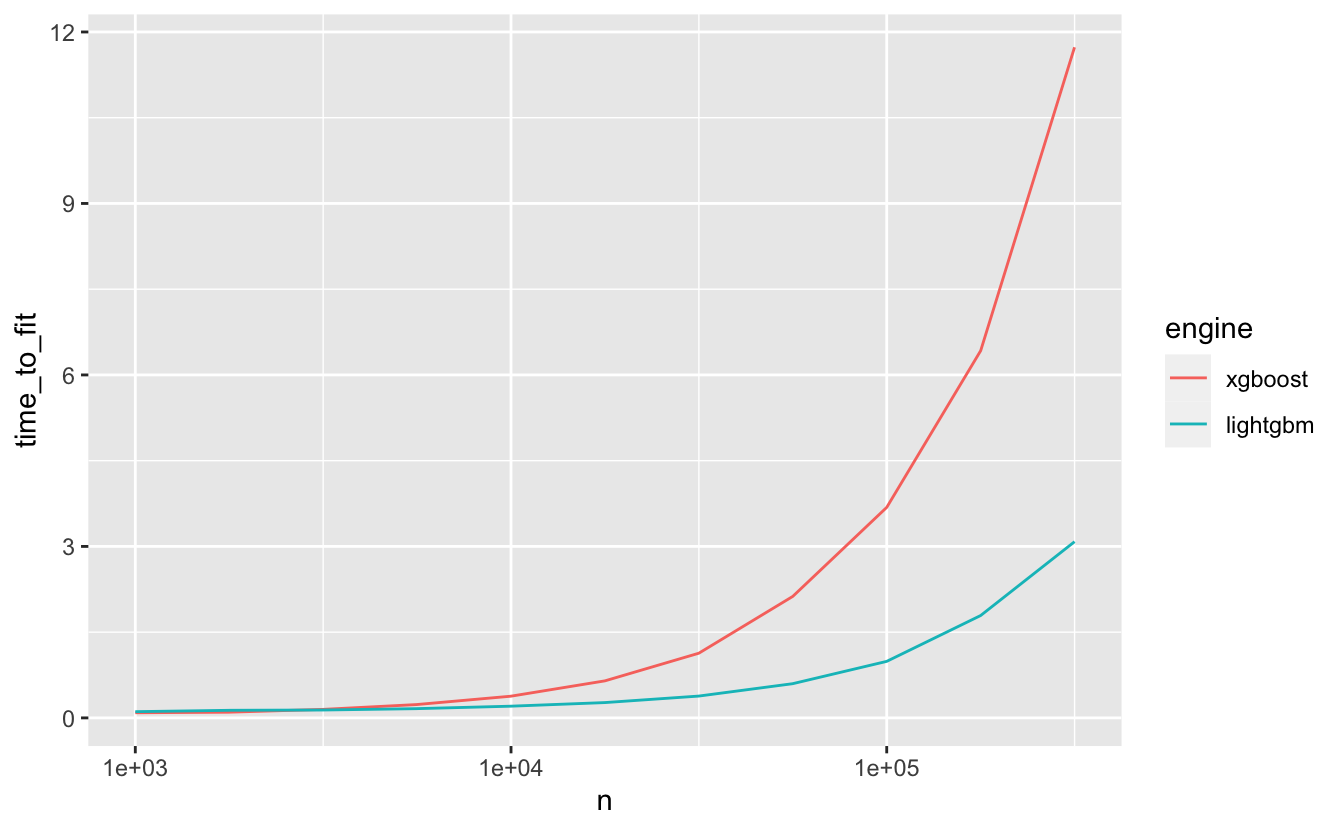
As we can see, the decrease in time-to-fit when using LightGBM as opposed to XGBoost becomes more notable as the number of rows in the training data increases.
Read more about this implementation of boosted trees in
?details_boost_tree_lightgbm.
Other Notes
This package is based off of the treesnip package by Daniel Falbel, Athos Damiani, and Roel M. Hogervorst. Users of that package will note that we have not included support for the catboost package. Unfortunately, the catboost R package is not on CRAN, so we’re not able to add support for the package for now. We’ll be keeping an eye on discussions in that development community and plan to support the package upon its release to CRAN!
Each of these model specs and engines have several arguments and tuning parameters that affect user experience and results greatly. We recommend reading about each of these parameters and tuning them when you find them relevant for your modeling use case.
Acknowledgements
A big thanks to Daniel Falbel, Athos Damiani, and Roel M. Hogervorst for their work on the treesnip package, on which this package is based. We’ve listed the treesnip authors as co-authors of bonsai in recognition of their help in laying the foundations for this project.
We’re also grateful for the wonderful package hex sticker by Amanda Petri!
Finally, thank you to those who have tested and provided feedback on the developmental versions of the package over the last couple months.
For those interested, the original paper introducing conditional inference trees describes and motivates these differences well. ↩︎