
We’re thrilled to announce the release of censored 0.2.0. censored is a parsnip extension package for survival models.
You can install it from CRAN with:
install.packages("censored")This blog post will introduce you to a new argument name, eval_time, and two new engines for fitting random forests and parametric survival models.
You can see a full list of changes in the release notes.
Introducing eval_time
As we continue to add support for survival analysis across tidymodels, we have seen a need to be more explicit about which time we mean when we say “time”: event time, observed time, censoring time, time at which to predict survival probability at? The last one is a particular mouthful. We now refer to this time as “evaluation time.” In preparation for dynamic survival performance metrics which can be calculated at different evaluation time points, the argument to set these evaluation time points for
predict() is now called eval_time instead of just time.
cox <- proportional_hazards() |>
set_engine("survival") |>
set_mode("censored regression") |>
fit(Surv(time, status) ~ ., data = lung)
pred <- predict(cox, lung[1:3, ], type = "survival", eval_time = c(100, 500))
pred
#> # A tibble: 3 × 1
#> .pred
#> <list>
#> 1 <tibble [2 × 2]>
#> 2 <tibble [2 × 2]>
#> 3 <tibble [2 × 2]>
The predictions follow the tidymodels principle of one row per observation, and the nested tibble contains the predicted survival probability, .pred_survival, as well as the corresponding evaluation time. The column for the evaluation time is now called .eval_time instead of .time.
pred$.pred[[2]]
#> # A tibble: 2 × 2
#> .eval_time .pred_survival
#> <dbl> <dbl>
#> 1 100 0.910
#> 2 500 0.422
New engines
censored contains engines for parametric, semi-parametric, and tree-based models. This release adds two new engines:
- the
"aorsf"engine for random forests viarand_forest() - the
"flexsurvspline"engine for parametric models viasurvival_reg()
New "aorsf" engine for rand_forest()
This engine has been contributed by Byron Jaeger and enables users to fit oblique random survival forests with the aorsf package. What’s with the oblique you ask?
Oblique describes how the decision trees that form the random forest make their splits at each node. If the split is based on a single predictor, the resulting tree is called axis-based because the split is perpendicular to the axis of the predictor. If the split is based on a linear combination of predictors, there is a lot more flexibility in how the data is split: the split does not need to be perpendicular to any of the predictor axes. Such trees are called oblique.
The documentation for the aorsf package includes a nice illustration of this with the splits for an axis-based tree on the left and an oblique tree on the right:
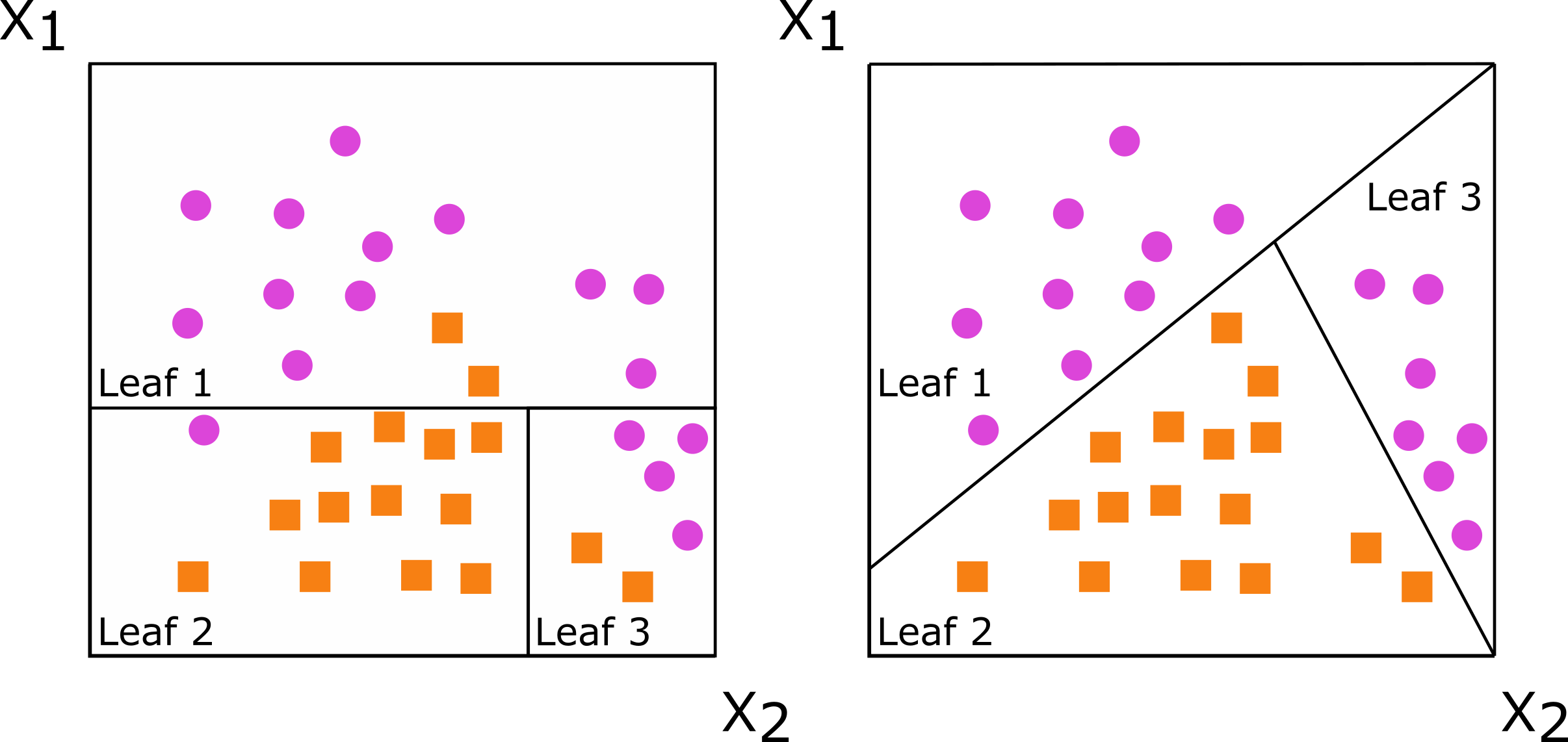
To fit such a model, set the engine for a random forest to "aorsf":
lung <- na.omit(lung)
forest <- rand_forest() |>
set_engine("aorsf") |>
set_mode("censored regression") |>
fit(Surv(time, status) ~ ., data = lung)
pred <- predict(forest, lung[1:3, ], type = "survival", eval_time = c(100, 500))
pred$.pred[[1]]
#> # A tibble: 2 × 2
#> .eval_time .pred_survival
#> <dbl> <dbl>
#> 1 100 0.928
#> 2 500 0.368
New "flexsurvspline" engine for survival_reg()
This engine has been contributed by
Matt Warkentin and enables users to fit a parametric survival model with splines via
flexsurv::flexsurvspline().
This model uses natural cubic splines to model a transformation of the survival function, e.g., the log cumulative hazard. This gives a lot more flexibility to a parametric model allowing us, for example, to represent more irregular hazard curves. Let’s illustrate that with a data set of survival times of breast cancer patients, based on the example from Jackson (2016).
The flexibility of the model is governed by k, the number of knots in the spline. We set scale = "odds" for a proportional hazards model.
data(bc, package = "flexsurv")
fit_splines <- survival_reg() |>
set_engine("flexsurvspline", k = 5, scale = "odds") |>
fit(Surv(recyrs, censrec) ~ group, data = bc)For comparison, we also fit a parametric model without splines.
fit_gengamma <- survival_reg(dist = "gengamma") |>
set_engine("flexsurv") |>
fit(Surv(recyrs, censrec) ~ group, data = bc)We can predict the hazard for the three levels of the prognostic group.
bc_groups <- tibble(group = c("Poor","Medium","Good"))
pred_splines <- predict(fit_splines, new_data = bc_groups, type = "hazard",
eval_time = seq(0.1, 8, by = 0.1)) |>
mutate(model = "splines") |>
bind_cols(bc_groups)
pred_gengamma <- predict(fit_gengamma, new_data = bc_groups, type = "hazard",
eval_time = seq(0.1, 8, by = 0.1)) |>
mutate(model = "gengamma") |>
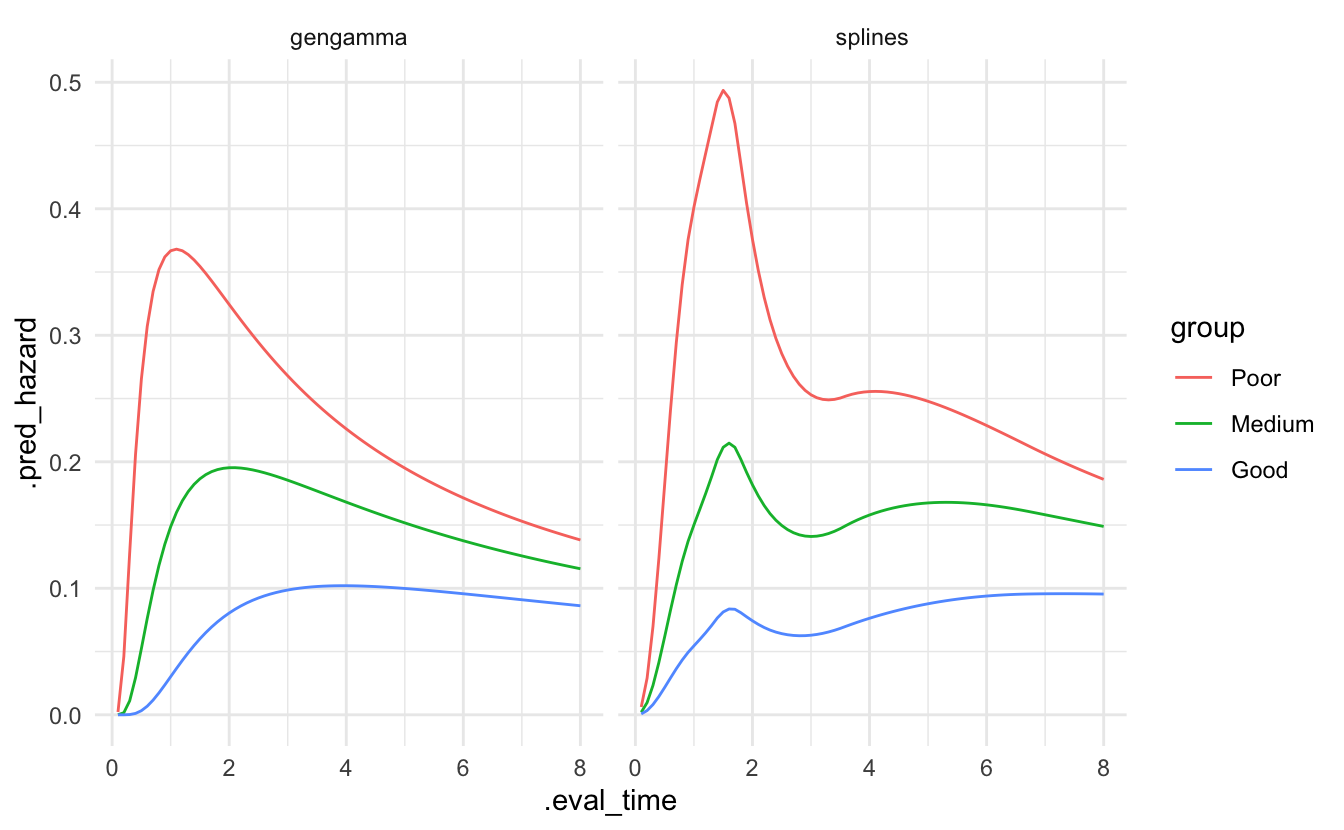
bind_cols(bc_groups)Plotting the predictions of both models shows a lot more flexibility in the splines model.
bind_rows(pred_splines, pred_gengamma) %>%
mutate(group = factor(group, levels = c("Poor","Medium","Good"))) |>
tidyr::unnest(cols = .pred) |>
ggplot() +
geom_line(aes(x = .eval_time, y = .pred_hazard, group = group, col = group)) +
facet_wrap(~ model)
Acknowledgements
Special thanks to Matt Warkentin and Byron Jaeger for the new engines! A big thank you to all the people who have contributed to censored since the release of v0.1.0:
@bcjaeger, @hfrick, @mattwarkentin, @simonpcouch, @therneau, and @topepo.