
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles.
library(tidymodels)
#> ── Attaching packages ──────────────────────────── tidymodels 0.1.4 ──
#> ✓ broom 0.7.10 ✓ rsample 0.1.1
#> ✓ dials 0.0.10 ✓ tibble 3.1.6
#> ✓ dplyr 1.0.7 ✓ tidyr 1.1.4
#> ✓ infer 1.0.0 ✓ tune 0.1.6
#> ✓ modeldata 0.1.1 ✓ workflows 0.2.4
#> ✓ parsnip 0.1.7 ✓ workflowsets 0.1.0
#> ✓ purrr 0.3.4 ✓ yardstick 0.0.9
#> ✓ recipes 0.1.17
#> ── Conflicts ─────────────────────────────── tidymodels_conflicts() ──
#> x purrr::discard() masks scales::discard()
#> x dplyr::filter() masks stats::filter()
#> x dplyr::lag() masks stats::lag()
#> x recipes::step() masks stats::step()
#> • Dig deeper into tidy modeling with R at https://www.tmwr.org
Starting at the beginning of this year, we now publish
regular updates here on the tidyverse blog summarizing what’s new in the tidymodels ecosystem. You can check out the
tidymodels tag to find all tidymodels blog posts here, including our roundup posts as well as those that are more focused. The purpose of these quarterly posts is to share useful new features and any updates you may have missed.
Since our last roundup post, there have been seven CRAN releases of tidymodels packages. You can install these updates from CRAN with:
install.packages(c("broom", "embed", "rsample", "shinymodels",
"tidymodels", "workflows", "yardstick"))
The NEWS files are linked here for each package; you’ll notice that some of these releases involve small bug fixes or internal changes that are not user-facing. We write code in these smaller, modular packages that we can release frequently both to make models easier to deploy and to keep our software easier to maintain. We know it may feel like a lot of moving parts to keep up with if you are a tidymodels user, so we want to highlight a couple of the more useful updates in these releases.
- broom
- embed
- rsample
- shinymodels
- the tidymodels metapackage itself
- workflows
- yardstick
Tools for tidymodels analyses
Several of these releases incorporate tools to reduce the overhead for getting started with your tidymodels analysis or for understanding your results more deeply. The new release of the tidymodels metapackage itself provides an R Markdown template. To use the tidymodels analysis template from RStudio, access through File -> New File -> R Markdown. This will open the dialog box where you can select from one of the available templates:

If you are not using RStudio, you’ll also need to install
Pandoc. Then, use the rmarkdown::draft() function to create the model card:
rmarkdown::draft(
"my_model_analysis.Rmd",
template = "model-analysis",
package = "tidymodels"
)
This template offers an opinionated guide on how to structure a basic modeling analysis from exploratory data analysis through evaluating your models. Your individual modeling analysis may require you to add to, subtract from, or otherwise change this structure, but you can consider this a general framework to start from.
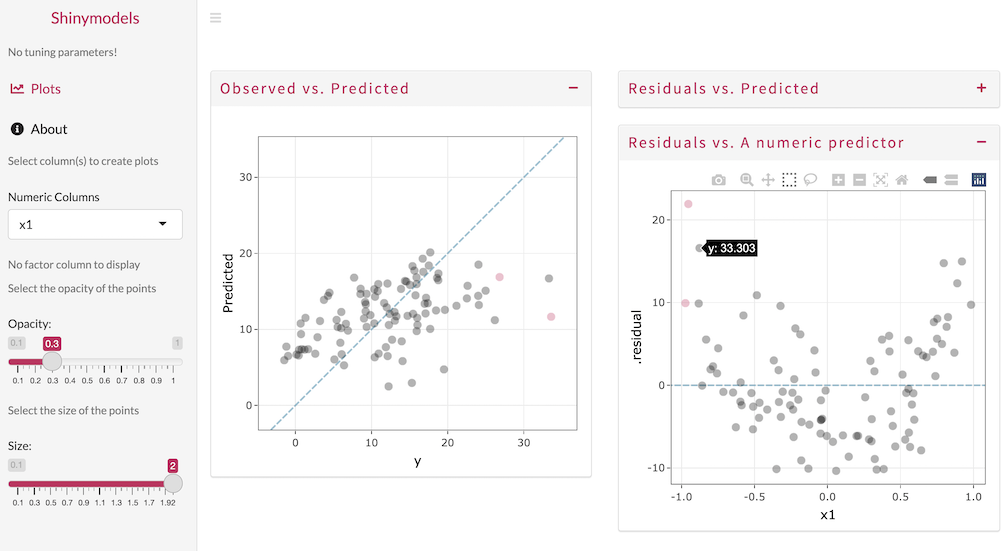
This quarter, the package shinymodels had its first CRAN release. This package was the focus of our tidymodels summer intern Shisham Adhikari in 2021, and it provides support for launching a Shiny app to interactively explore tuning or resampling results.
Make your own rsample split objects
The data resampling infrastructure provided by the
rsample package has always worked well when you start off with a dataset to split into training and testing. However, we heard from users that in some situations they have training and testing sets determined by other processes, or need to create their data split using more complex conditions. The latest release of rsample provides more fluent and flexible support for custom rsplit creation that sets you up for the rest of your tidymodels analysis. For example, you can create a split object from two dataframes.
library(gapminder)
year_split <-
make_splits(
gapminder %>% filter(year <= 2000),
gapminder %>% filter(year > 2000)
)
year_split
#> <Analysis/Assess/Total>
#> <1420/284/1704>
testing(year_split)
#> # A tibble: 284 × 6
#> country continent year lifeExp pop gdpPercap
#> <fct> <fct> <int> <dbl> <int> <dbl>
#> 1 Afghanistan Asia 2002 42.1 25268405 727.
#> 2 Afghanistan Asia 2007 43.8 31889923 975.
#> 3 Albania Europe 2002 75.7 3508512 4604.
#> 4 Albania Europe 2007 76.4 3600523 5937.
#> 5 Algeria Africa 2002 71.0 31287142 5288.
#> 6 Algeria Africa 2007 72.3 33333216 6223.
#> 7 Angola Africa 2002 41.0 10866106 2773.
#> 8 Angola Africa 2007 42.7 12420476 4797.
#> 9 Argentina Americas 2002 74.3 38331121 8798.
#> 10 Argentina Americas 2007 75.3 40301927 12779.
#> # … with 274 more rows
You can alternatively
create a split using a list of indices; this make_splits() flexibility is good for when the defaults in initial_split() and initial_time_split() are not appropriate. We also added a
new function validation_time_split() to create a single validation resample, much like validation_split(), but taking the first prop samples for training.
Survey says…
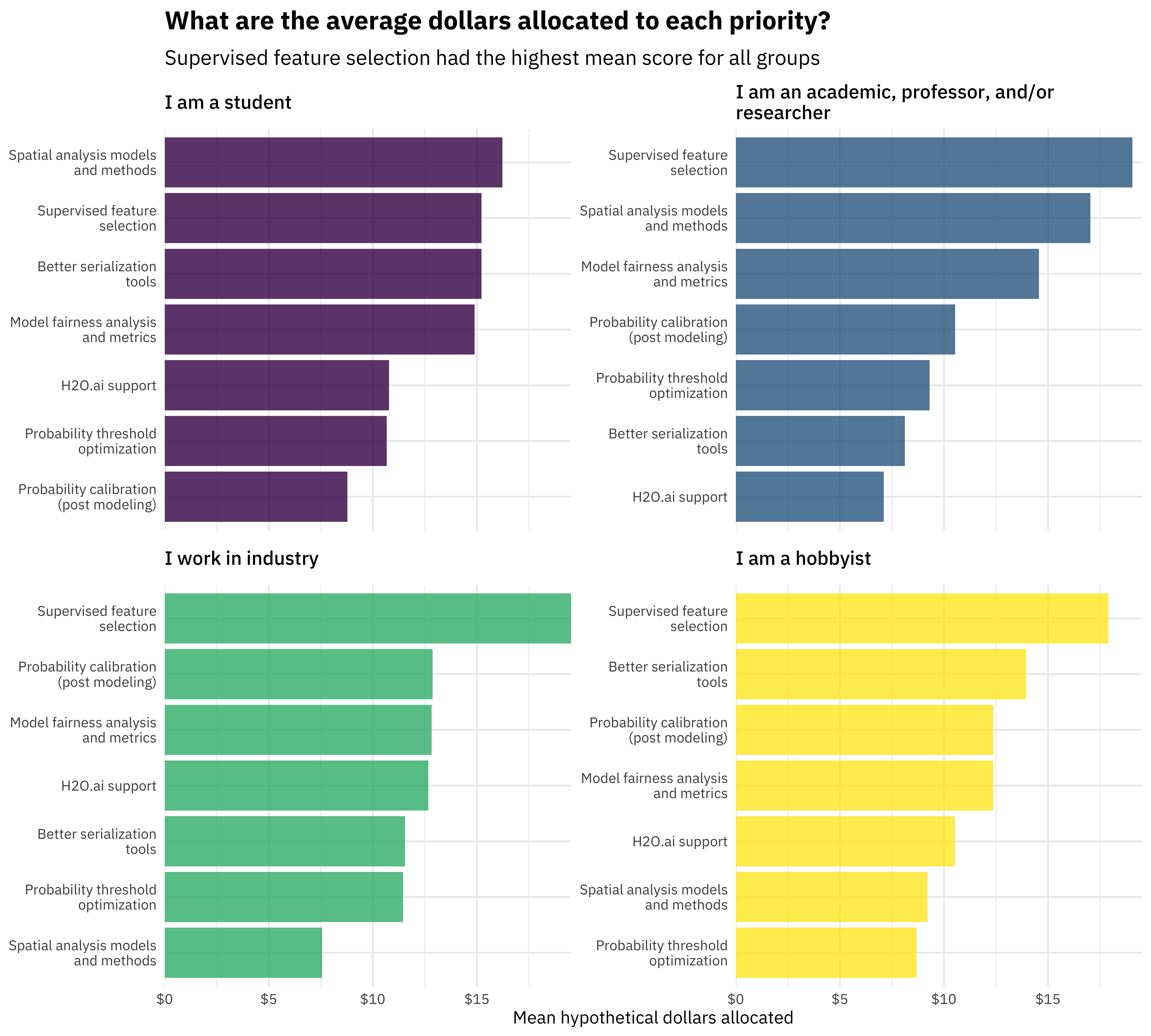
This fall, we launched our second tidymodels survey to gather community input on our priorities for 2022. Thank you so much to everyone who shared their opinion! Over 600 people completed the survey, a significant increase from last year, and the top three requested features overall are:
-
Supervised feature selection: This includes basic supervised filtering methods as well as techniques such as recursive feature elimination.
-
Model fairness analysis and metrics: Techniques to measure if there are biases in model predictions that treat groups or individuals unfairly.
-
Post modeling probability calibration: Methods to characterize (and correct) probability predictions to make sure that probability estimates reflect the observed event rate(s).
You can also check out our full analysis of the survey results.
Acknowledgements
We’d like to extend our thanks to all of the contributors who helped make these releases during Q4 possible!
-
broom: @gjones1219, @gravesti, @gregmacfarlane, @ilapros, @jamesrrae, @juliasilge, @lcgodoy, @RobBinS83, @simonpcouch, @statzhero, @vincentarelbundock, and @wviechtb
-
embed: @EmilHvitfeldt, @jlmelville, @juliasilge, and @topepo
-
rsample: @EmilHvitfeldt, @jmgirard, @juliasilge, @mmp3, and @Shafi2016
-
shinymodels: @romainfrancois, and @topepo
-
tidymodels: @agronomofiorentini, @AshleyHenry15, and @topepo
-
workflows: @DavisVaughan, @dkgaraujo, @hfrick, and @juliasilge
-
yardstick: @DavisVaughan, @joeycouse, @juliasilge, @mattwarkentin, @romainfrancois, and @topepo