
The
tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles. We now publish
regular updates here on the tidyverse blog summarizing recent developments in the tidymodels ecosystem. You can check out the
tidymodels tag to find all tidymodels blog posts here, including those that focus on a single package or more major releases. The purpose of these roundup posts is to keep you informed about any releases you may have missed and useful new functionality as we maintain these packages.
Since our last roundup post, there have been 9 CRAN releases of tidymodels packages. You can install these updates from CRAN with:
install.packages(c("baguette", "broom", "dials",
"modeldata", "poissonreg", "recipes",
"rules", "stacks", "textrecipes"))
The NEWS files are linked here for each package; you’ll notice that many of these releases involve small updates for CRAN policy or changes that are not user-facing. We write code in these smaller, modular packages that we can release frequently to make models easier to deploy and our software easier to maintain, but it can be a lot to keep up with as a user! We want to take the opportunity here to highlight a couple of more important changes in these releases.
New parameter objects
The dials package is one that you might not have thought much about yet, even if you are a regular tidymodels user. It is an infrastructure package for creating and managing hyperparameters as well as grids (both regular and non-regular) of hyperparameters. The most recent release of dials includes several new parameters, and Hannah Frick is now the package maintainer.
One of the new parameters in this release is
stop_iter(), the number of iterations without improvement before
“early stopping”.
library(tidymodels)
#> ── Attaching packages ──────────────────────────── tidymodels 0.1.3 ──
#> ✓ broom 0.7.9 ✓ rsample 0.1.0
#> ✓ dials 0.0.10 ✓ tibble 3.1.4
#> ✓ dplyr 1.0.7 ✓ tidyr 1.1.3
#> ✓ infer 1.0.0 ✓ tune 0.1.6
#> ✓ modeldata 0.1.1 ✓ workflows 0.2.3
#> ✓ parsnip 0.1.7 ✓ workflowsets 0.1.0
#> ✓ purrr 0.3.4 ✓ yardstick 0.0.8
#> ✓ recipes 0.1.17
#> ── Conflicts ─────────────────────────────── tidymodels_conflicts() ──
#> x purrr::discard() masks scales::discard()
#> x dplyr::filter() masks stats::filter()
#> x dplyr::lag() masks stats::lag()
#> x recipes::step() masks stats::step()
#> • Use tidymodels_prefer() to resolve common conflicts.
stop_iter()
#> # Iterations Before Stopping (quantitative)
#> Range: [3, 20]
You don’t typically use parameters from dials like this, though. Instead, the infrastructure these parameters provide is what allows us to fluently tune our hyperparameters. For example, we can use data on high-performance computing jobs to predict the class of those jobs with xgboost, choosing to try out different values for early stopping (along with another hyperparameter mtry).
data(hpc_data)
hpc_folds <- vfold_cv(hpc_data, strata = class)
hpc_formula <- class ~ compounds + input_fields + iterations + num_pending + hour
stopping_spec <-
boost_tree(
trees = 500,
learn_rate = 0.02,
mtry = tune(),
stop_iter = tune()
) %>%
set_engine("xgboost", validation = 0.2) %>%
set_mode("classification")
early_stop_wf <- workflow(hpc_formula, stopping_spec)
We can now tune this workflow() over the resamples hpc_folds and find out which values for the hyperparameters turned out best.
doParallel::registerDoParallel()
set.seed(123)
early_stop_rs <- tune_grid(early_stop_wf, hpc_folds)
#> i Creating pre-processing data to finalize unknown parameter: mtry
show_best(early_stop_rs, "roc_auc")
#> # A tibble: 5 × 8
#> mtry stop_iter .metric .estimator mean n std_err .config
#> <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 3 13 roc_auc hand_till 0.887 10 0.00337 Preprocessor…
#> 2 2 11 roc_auc hand_till 0.887 10 0.00414 Preprocessor…
#> 3 2 15 roc_auc hand_till 0.886 10 0.00342 Preprocessor…
#> 4 4 7 roc_auc hand_till 0.885 10 0.00365 Preprocessor…
#> 5 4 9 roc_auc hand_till 0.884 10 0.00353 Preprocessor…
In this case, the best value for the early stopping parameter is 13.
This recent screencast demonstrates how to tune early stopping for xgboost as well.
Several of the new parameter objects in this version of dials are prep work for supporting more options in tidymodels, such as tuning yet more hyperparameters of xgboost (like L1 and L2 penalties and whether to balance classes), generalized additive models, discriminant analysis models, recursively partitioned models, and a recipe step for sparse PCA. Stay tuned for more on these new options!
Improvements to recipes
The most recent release of recipes is a robust one, including new recipe steps, bug fixes, documentation improvements, and better performance. You can dig into the NEWS file for more details, but check out a few of the most important changes.
We added a new recipe step for creating sine and cosine features,
step_harmonic(). We can use this to analyze data with periodic features, like
the annual number of sunspots. The sunspot.year dataset has an observation every year, and the solar cycle is about 11 years long.
data(sunspot.year)
sunspots <-
tibble(year = 1700:1988,
n_sunspot = sunspot.year)
sun_split <- initial_time_split(sunspots)
sun_train <- training(sun_split)
sun_test <- testing(sun_split)
sunspots_rec <-
recipe(n_sunspot ~ year, data = sun_train) %>%
step_harmonic(year, frequency = 1 / 11, cycle_size = 1,
role = "predictor",
keep_original_cols = FALSE)
lm_spec <- linear_reg()
sunspots_wf <- workflow(sunspots_rec, lm_spec)
sunspots_fit <- fit(sunspots_wf, sun_train)
sunspots_fit
#> ══ Workflow [trained] ════════════════════════════════════════════════
#> Preprocessor: Recipe
#> Model: linear_reg()
#>
#> ── Preprocessor ──────────────────────────────────────────────────────
#> 1 Recipe Step
#>
#> • step_harmonic()
#>
#> ── Model ─────────────────────────────────────────────────────────────
#>
#> Call:
#> stats::lm(formula = ..y ~ ., data = data)
#>
#> Coefficients:
#> (Intercept) year_sin_1 year_cos_1
#> 42.904 9.691 20.504
We can now predict with this fitted linear model on the most recent years.
sunspots_fit %>%
augment(sun_test) %>%
select(year, n_sunspot, .pred) %>%
pivot_longer(-year) %>%
ggplot(aes(year, value, color = name)) +
geom_line(alpha = 0.8, size = 1.2) +
theme_minimal() +
labs(x = NULL, y = "Number of sunspots", color = NULL)
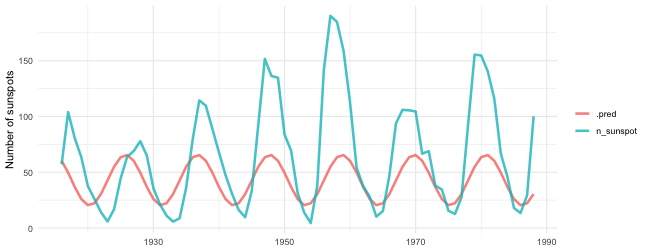
Looks like there have been more sunspots in recent decades compared to the past!
Another new recipe step is
step_dummy_multi_choice(), while
step_kpca() was “un-deprecated” and
step_spatialsign() and
step_geodist() were improved.
If you
build your own recipe steps, the new
recipes_eval_select() function is now available, powering the tidyselect semantics specific to recipes. The older terms_select() function is now deprecated in favor of this new helper.
The recipes package is fairly extensive, and we have recently invested time and energy in refining the documentation to make it more navigable and clear, as well as easier to maintain and contribute to. Specific documentation pages with recent updates you may find helpful include:
Reexamining example datasets
One of the tidymodels packages is
modeldata, where we keep example datasets for vignettes, examples, and other similar uses. We have included two datasets, okc and okc_text, in modeldata based on real user data from the dating website OkCupid.
This dataset was sourced from Kim and Escobedo-Land (2015). Permission to use this dataset was explicitly granted by OkCupid, but since that time, concerns have been raised about the ethics of using this or similar data sets, for example to identify individuals. Xiao and Ma (2021) specifically address the possible misuse of this particular dataset, and we now agree that it isn’t a good option to use for examples or teaching. In the most recent release of modeldata, we have marked these datasets as deprecated. We have removed them from the development version of the package on GitHub, and they will be removed entirely in the next CRAN release. We especially want to thank Albert Kim, one of the authors of the original paper, for his thoughtful and helpful discussion.
One of the reasons we found the OkCupid dataset useful was that it included multiple text columns per observation, so removing these two datasets motivated us to look for a new option to include instead. We landed on
metadata for modern artwork from the Tate Gallery; if you used okc_text in the past, we recommend switching to tate_text. For example, we can count how many of these examples of artwork involve paper or canvas.
data(tate_text)
library(textrecipes)
paper_or_canvas <- c("paper", "canvas")
recipe(~ ., data = tate_text) %>%
step_tokenize(medium) %>%
step_stopwords(medium, custom_stopword_source = paper_or_canvas, keep = TRUE) %>%
step_tf(medium) %>%
prep() %>%
bake(new_data = NULL) %>%
select(artist, year, starts_with("tf"))
#> # A tibble: 4,284 × 4
#> artist year tf_medium_canvas tf_medium_paper
#> <fct> <dbl> <dbl> <dbl>
#> 1 Absalon 1990 0 0
#> 2 Auerbach, Frank 1990 0 1
#> 3 Auerbach, Frank 1990 0 1
#> 4 Auerbach, Frank 1990 0 1
#> 5 Auerbach, Frank 1990 1 0
#> 6 Ayres, OBE Gillian 1990 1 0
#> 7 Barlow, Phyllida 1990 0 1
#> 8 Baselitz, Georg 1990 0 1
#> 9 Beattie, Basil 1990 1 0
#> 10 Beuys, Joseph 1990 0 1
#> # … with 4,274 more rows
This artwork metadata was a Tidy Tuesday dataset earlier this year.
Acknowledgements
We’d like to extend our thanks to all of the contributors who helped make these releases during Q3 possible!
baguette: @DavisVaughan, @jennybc, @juliasilge, and @topepo
broom: @bcallaway11, @billdenney, @brshallo, @corybrunson, @crsh, @gregmacfarlane, @hfrick, @ilapros, @jamesrrae, @jennybc, @jthomasmock, @kaseyzapatka, @krivit, @LukasWallrich, @oskasf, @simonpcouch, and @tarensanders
dials: @camroberts, @driapitek, @hfrick, @jennybc, @joeycouse, @Steviey, @tonyk7440, and @topepo
modeldata: @EmilHvitfeldt, @hfrick, @jennybc, @juliasilge, and @topepo
recipes: @AndrewKostandy, @asiripanich, @atusy, @avrenli2, @czopluoglu, @DavisVaughan, @DesmondChoy, @EmilHvitfeldt, @felipeangelimvieira, @hfrick, @jennybc, @joeycouse, @juliasilge, @kadyb, @mmp3, @MrFlick, @NikKrieger, @PathosEthosLogos, @simonschoe, @SlowMo24, @topepo, @vspinu, and @yyhyun64
stacks: @bensoltoff, @dgrtwo, @JoeSydlowski, @PathosEthosLogos, and @simonpcouch
textrecipes: @dgrtwo, @EmilHvitfeldt, @jcragy, @jennybc, and @topepo