
We’re pleased to announce the release of styler 1.0.0. styler is a source code formatter - a package to format R code according to a style guide. It defaults to our implementation of the tidyverse style guide, but there is plenty of flexibility for a user to specify their own style. A coherent style is important for consistency and legibility. Just as it is important to putspcesbetweenwords. You can install styler from CRAN:
install.packages("styler")styler can style text, single files, packages and entire R source trees with the following functions:
style_text()styles a character vector.style_file()styles R and Rmd files.style_dir()styles all R and/or Rmd files in a directory.style_pkg()styles the source files of an R package.- An RStudio Addin that styles the active R or Rmd file, the current package or the highlighted code.
The following screenshot illustrates how the active file can be styled conveniently with the RStudio Addin.
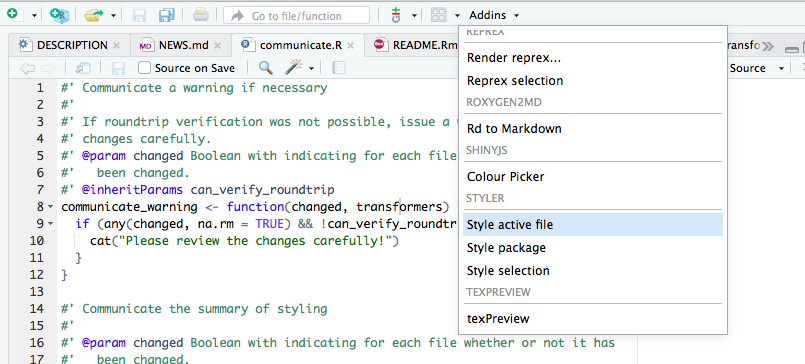
Note that all functions except style_text() modify in place, that is, they overwrite the source. style_file() for example modifies the files it is given without creating a backup copy. We therefore strongly advise to use version control in conjunction with styler and consider the implications this might have on your workflow.
styling options
A distinguishing feature of styler is its flexibility. The following options are available:
scope. What is to be styled, e.g. just spacing or also indention, line breaks, tokens?strict. How strictly should the rules be applied?math_token_spacing. Granular control for spacing around math tokens.reindention. Allows to set the indention of certain regex patterns manually.
We will briefly describe all of them below.
scope
scope can take one of the following values:
- “none”: Performs no transformation at all.
- “spaces”: Manipulates spacing between tokens on the same line.
- “indention”: In addition to “spaces”, this option also manipulates the indention level.
- “line_breaks”: In addition to “indention”, this option also manipulates line breaks.
- “tokens”: In addition to “line_breaks”, this option also manipulates tokens.
Hence, scope < "tokens" will never change code in the sense that the expression remains the same before and after styling, as only spaces and line breaks between the tokens are modified. styler can internally validate the styling, so you can be sure that it has not broken your code. Although extensively tested, we recommend to inspect the styling result with scope = "tokens", since in this case, an automatic validation is not possible.
Let’s now see a few examples. We can limit ourselves to styling just spacing information:
library("styler")
style_text("a=3; 2", scope = "spaces")a = 3; 2Or, on the other extreme of the scale, styling spaces, indention, line breaks and tokens:
style_text("a=3; 2", scope = "tokens")a <- 3
2For the reader’s convenience, we will now switch the mode of display. In the new mode, the above example looks like this:
# Before
a=3; 2# After style_text(..., scope = tokens)
a <- 3
2Where ... refers to the code to style.
In the next example, we want to style spaces and indention, but not line breaks and tokens:
# Before
a= function( x) {
'x'
}# After style_text(..., scope = indention)
a = function(x) {
'x'
}strict
Another option that is helpful to determine the level of ‘invasiveness’ is strict. If set to TRUE, spaces and line breaks before or after tokens are set to either zero or one. However, in some situations, this might be undesirable (so we set strict = FALSE), as the following example shows:
# Before
data_frame(
small = 2 ,
medium = 4,#comment without space
large =6
)# After style_text(..., strict = FALSE)
data_frame(
small = 2,
medium = 4, # comment without space
large = 6
)We prefer to keep the equal sign after “small”, “medium” and “large” aligned, so we set strict = FALSE to set spacing to at least one around =.
Also, with scope >= "line_breaks", strict = TRUE will break the lines in the following call, whereas strict = FALSE will leave them as is:
# Before
do_a_long_and_complicated_fun_cal('which', has, way, to,
'and longer then lorem ipsum in its full length'
)# After
do_a_long_and_complicated_fun_cal(
"which", has, way, to,
"and longer then lorem ipsum in its full length"
)In addition, the strict option also adds braces (if scope = "tokens") to conditional statements if they are multi-line:
# Before
if (set_q(x))
3 else
5# After style_text(..., strict = TRUE)
if (set_q(x)) {
3
} else {
5
}math token spacing
styler can identify and handle unary operators and other math tokens:
# Before
1++1-1-1/2# After
1 + +1 - 1 - 1 / 2This is tidyverse style. However, styler offers very granular control for math token spacing. Assuming you like spacing around + and -, but not around / and * and ^. This can be achieved as follows:
# Before
1++1/2*2^2 # After style_text(..., math_token_spacing = list(one = c("'+'", "'-'"), zero = c("'/'", "'*'", "'^'")))
1 + +1/2*2^2reindention
You can set the indention of lines that match a certain regular expression manually. For example, if you don’t want comments starting with ### to be indented, you can formulate an unindention rule:
# Before
a <- function() {
### not to be indented
# indent normally
33
}# After style_text(..., reindention = list(regex_pattern = "^###", indention = 0, comments_only = TRUE))
a <- function() {
### not to be indented
# indent normally
33
}These are options that allow flexible reformatting. You can even go further, as described in the “Customizing styler” vignette.
A few more examples
Now that you know that the rules can be applied in a flexible fashion, let’s focus on scope = "tokens" and strict = TRUE and illustrate how specific rules of the tidyverse style guide are implemented.
Spaces are placed around operators such as =, after (but not before) commas, before comments etc.
# Before
split_fast<-split_into_fractions(target="fast",origin ="E2-k3",...)#comment# After
split_fast <- split_into_fractions(target = "fast", origin = "E2-k3", ...) # commentFunction declarations are indented if multi-line:
# Before
my_fun <- function(x,
y,
z) {
just(z)
}# After
my_fun <- function(x,
y,
z) {
just(z)
}styler can also format complicated expressions that involve line breaking and indention based on both brace expressions and operators:
# Before
if (x >3) {stop("this is an error")} else {
c(there_are_fairly_long,
1 / 33 *
2 * long_long_variable_names)%>% k(
) }# After
if (x > 3) {
stop("this is an error")
} else {
c(
there_are_fairly_long,
1 / 33 *
2 * long_long_variable_names
) %>% k()
}Lines are broken after ( if a function call spans multiple lines:
# Before
do_a_long_and_complicated_fun_cal("which", has, way, to,
"and longer then lorem ipsum in its full length"
)# After
do_a_long_and_complicated_fun_cal(
"which", has, way, to,
"and longer then lorem ipsum in its full length"
)styler replaces = with <- for assignment if necessary:
# Before
one = 3
data_frame(a = 3)# After
one <- 3
data_frame(a = 3)It also handles single quotes according to the tidyverse style guide:
# Before
'one string'
'one string in a "string"'
"one string in a 'string'"
# After
"one string"
'one string in a "string"'
"one string in a 'string'"Braces are added to function calls in pipes:
# Before
a %>%
b %>%
c# After
a %>%
b() %>%
c()tidyeval syntax is handled properly:
# Before
mtcars %>%
group_by(!!!my_vars)# After
mtcars %>%
group_by(!!!my_vars)That was a quick overview of styler. Please feel free to grab styler from CRAN, run it on your own package and tell us what you think.