
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles.
Since the beginning of 2021, we have been publishing
quarterly updates here on the tidyverse blog summarizing what’s new in the tidymodels ecosystem. The purpose of these regular posts is to share useful new features and any updates you may have missed. You can check out the
tidymodels tag to find all tidymodels blog posts here, including our roundup posts as well as those that are more focused, like these posts from the past couple of months:
- Survival analysis for time-to-event data with tidymodels
- Fair machine learning with tidymodels
- tune 1.2.0
Additionally, we have published several related articles on tidymodels.org:
- How long until building complaints are dispositioned? A survival analysis case study
- Dynamic Performance Metrics for Event Time Data
- Accounting for Censoring in Performance Metrics for Event Time Data
- Are GPT detectors fair? A machine learning fairness case study
- Fair prediction of hospital readmission: a machine learning fairness case study
- Confidence Intervals for Performance Metrics
Since our last roundup post, there have been CRAN releases of 21 tidymodels packages. Here are links to their NEWS files:
- baguette (1.0.2)
- brulee (0.3.0)
- butcher (0.3.4)
- censored (0.3.0)
- dials (1.2.1)
- embed (1.1.4)
- finetune (1.2.0)
- hardhat (1.3.1)
- modeldata (1.3.0)
- parsnip (1.2.1)
- probably (1.0.3)
- recipes (1.0.10)
- rsample (1.2.1)
- shinymodels (0.1.1)
- stacks (1.0.4)
- tidyclust (0.2.1)
- tidymodels (1.2.0)
- tune (1.2.0)
- workflows (1.1.4)
- workflowsets (1.1.0)
- yardstick (1.3.1)
We’ll highlight a few especially notable changes below: new prediction options in censored, consistency in augmenting parsnip models and workflows, as well as a new autoplot type for workflow sets.
New prediction options in censored
As part of the framework-wide integration of survival analysis, the parsnip extension package censored has received some love in the form of new prediction options.
Random forests with the "aorsf" engine can now predict survival time, thanks to the new feature in the
aorsf package itself. This means that all engines in censored can now predict survival time.
Let’s predict survival time for the first five rows of the lung cancer dataset, survival analysis’ mtcars.
rf_spec <- rand_forest() |>
set_engine("aorsf") |>
set_mode("censored regression")
rf_fit <- rf_spec |>
fit(Surv(time, status) ~ age + sex, data = lung)
lung_5 <- lung[1:5, ]
predict(rf_fit, new_data = lung_5, type = "time")
#> # A tibble: 5 × 1
#> .pred_time
#> <dbl>
#> 1 217.
#> 2 240.
#> 3 236.
#> 4 236.
#> 5 254.
Some models allow for predictions based on different values for tuning parameter without having to refit the model. In parsnip, we refer to this as
“the submodel trick." Some of those models are regularized models fitted with the
glmnet engine. In censored, the corresponding
multi_predict() method has now gained the prediction types "time" and "raw" in addition to the existing types "survival" and "linear_pred".
Let’s fit a regularized Cox model to illustrate. Note how we set the penalty to a fixed value of 0.1.
cox_fit <- proportional_hazards(penalty = 0.1) |>
set_engine("glmnet") |>
set_mode("censored regression") |>
fit(Surv(time, status) ~ ., data = lung)Predictions made with
predict() use that penalty value of 0.1. With
multi_predict(), we can change that value to something different without having to refit. Conveniently, we can predict for multiple penalty values as well.
predict(cox_fit, new_data = lung_5, type = "time")
#> # A tibble: 5 × 1
#> .pred_time
#> <dbl>
#> 1 NA
#> 2 425.
#> 3 NA
#> 4 350.
#> 5 NA
mpred <- multi_predict(cox_fit, new_data = lung_5, type = "time",
penalty = c(0.01, 0.1))
mpred
#> # A tibble: 5 × 1
#> .pred
#> <list>
#> 1 <tibble [2 × 2]>
#> 2 <tibble [2 × 2]>
#> 3 <tibble [2 × 2]>
#> 4 <tibble [2 × 2]>
#> 5 <tibble [2 × 2]>
The resulting tibble is nested by observation to follow the convention of one row per observation. For each observation, the predictions are stored in a tibble containing the penalty value along with the prediction.
mpred$.pred[[2]]
#> # A tibble: 2 × 2
#> penalty .pred_time
#> <dbl> <dbl>
#> 1 0.01 461.
#> 2 0.1 425.
You can see that the predicted value from
predict() matches the predicted value from
multi_predict() with a penalty of 0.1.
Consistent augment() for workflows and parsnip models
If you are interested in exploring predictions in relation to predictors,
augment() is your extended
predict() method: it will augment the inputted dataset with its predictions. For classification, it will add hard class predictions as well as class probabilities. For regression, it will add the numeric prediction. If the outcome variable is part of the dataset, it also calculates residuals. This has already been the case for fitted parsnip models, and the
augment() method for workflows will now also calculate residuals.
spec_fit <- fit(linear_reg(), mpg ~ ., mtcars)
wflow_fit <- workflow(mpg ~ ., linear_reg()) %>% fit(mtcars)
augment(spec_fit, mtcars)
#> # A tibble: 32 × 13
#> .pred .resid mpg cyl disp hp drat wt qsec vs am gear
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 22.6 -1.60 21 6 160 110 3.9 2.62 16.5 0 1 4
#> 2 22.1 -1.11 21 6 160 110 3.9 2.88 17.0 0 1 4
#> 3 26.3 -3.45 22.8 4 108 93 3.85 2.32 18.6 1 1 4
#> 4 21.2 0.163 21.4 6 258 110 3.08 3.22 19.4 1 0 3
#> 5 17.7 1.01 18.7 8 360 175 3.15 3.44 17.0 0 0 3
#> 6 20.4 -2.28 18.1 6 225 105 2.76 3.46 20.2 1 0 3
#> 7 14.4 -0.0863 14.3 8 360 245 3.21 3.57 15.8 0 0 3
#> 8 22.5 1.90 24.4 4 147. 62 3.69 3.19 20 1 0 4
#> 9 24.4 -1.62 22.8 4 141. 95 3.92 3.15 22.9 1 0 4
#> 10 18.7 0.501 19.2 6 168. 123 3.92 3.44 18.3 1 0 4
#> # ℹ 22 more rows
#> # ℹ 1 more variable: carb <dbl>
augment(wflow_fit, mtcars)
#> # A tibble: 32 × 13
#> .pred .resid mpg cyl disp hp drat wt qsec vs am gear
#> * <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 22.6 -1.60 21 6 160 110 3.9 2.62 16.5 0 1 4
#> 2 22.1 -1.11 21 6 160 110 3.9 2.88 17.0 0 1 4
#> 3 26.3 -3.45 22.8 4 108 93 3.85 2.32 18.6 1 1 4
#> 4 21.2 0.163 21.4 6 258 110 3.08 3.22 19.4 1 0 3
#> 5 17.7 1.01 18.7 8 360 175 3.15 3.44 17.0 0 0 3
#> 6 20.4 -2.28 18.1 6 225 105 2.76 3.46 20.2 1 0 3
#> 7 14.4 -0.0863 14.3 8 360 245 3.21 3.57 15.8 0 0 3
#> 8 22.5 1.90 24.4 4 147. 62 3.69 3.19 20 1 0 4
#> 9 24.4 -1.62 22.8 4 141. 95 3.92 3.15 22.9 1 0 4
#> 10 18.7 0.501 19.2 6 168. 123 3.92 3.44 18.3 1 0 4
#> # ℹ 22 more rows
#> # ℹ 1 more variable: carb <dbl>
Both methods also append on the left-hand side of the data frame, rather than the right-hand side. This means that prediction columns are always visible when printed, even for data frames with many columns. As you might expect, the order of the columns is the same for both methods as well.
New autoplot type for workflow sets
Many tidymodels objects have
autoplot() methods for quickly getting a sense of the most important aspects of an object. For workflow sets, the method shows the value of the calculated performance metrics, as well as the respective rank of each workflow in the set. Let’s put together a workflow set on the actual mtcars data and take a look at the default autoplot.
mt_rec <- recipe(mpg ~ ., mtcars)
mt_rec2 <- mt_rec |> step_normalize(all_numeric_predictors())
mt_rec3 <- mt_rec |> step_YeoJohnson(all_numeric_predictors())
wflow_set <- workflow_set(
list(plain = mt_rec, normalize = mt_rec2, yeo_johnson = mt_rec3),
list(linear_reg())
)
set.seed(1)
wflow_set_fit <- workflow_map(
wflow_set,
"fit_resamples",
resamples = bootstraps(mtcars)
)
autoplot(wflow_set_fit)
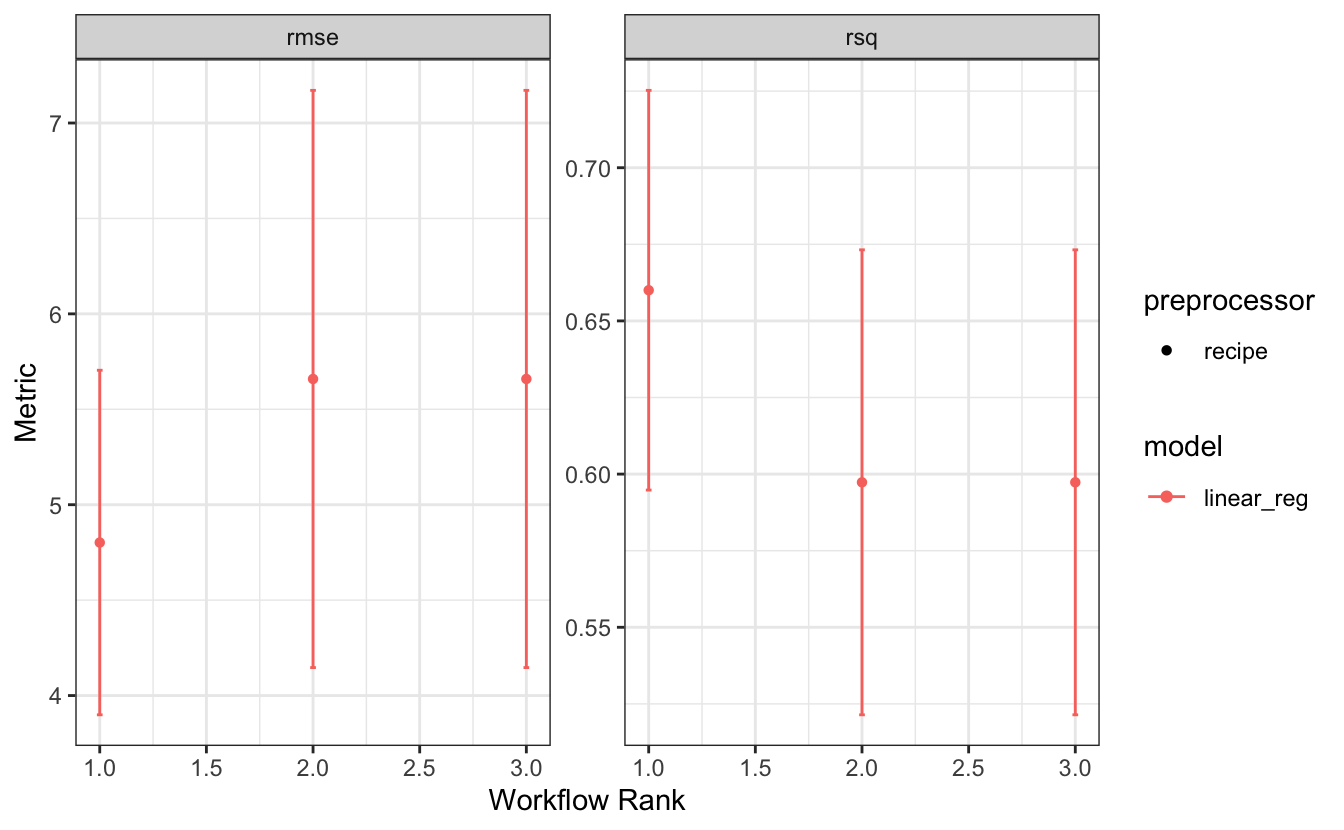
This allows you to grasp the metric values and rank of a workflow and let’s you distinguish the type of preprocessor and model. In our case, we only have one type of model, and even just one type of preprocessor, a recipe. What we are much more interested in is which recipe corresponds to which rank. The new option of type = "wflow_id" lets us see which values and ranks correspond with which workflow and thus also with which recipe.
autoplot(wflow_set_fit, type = "wflow_id")
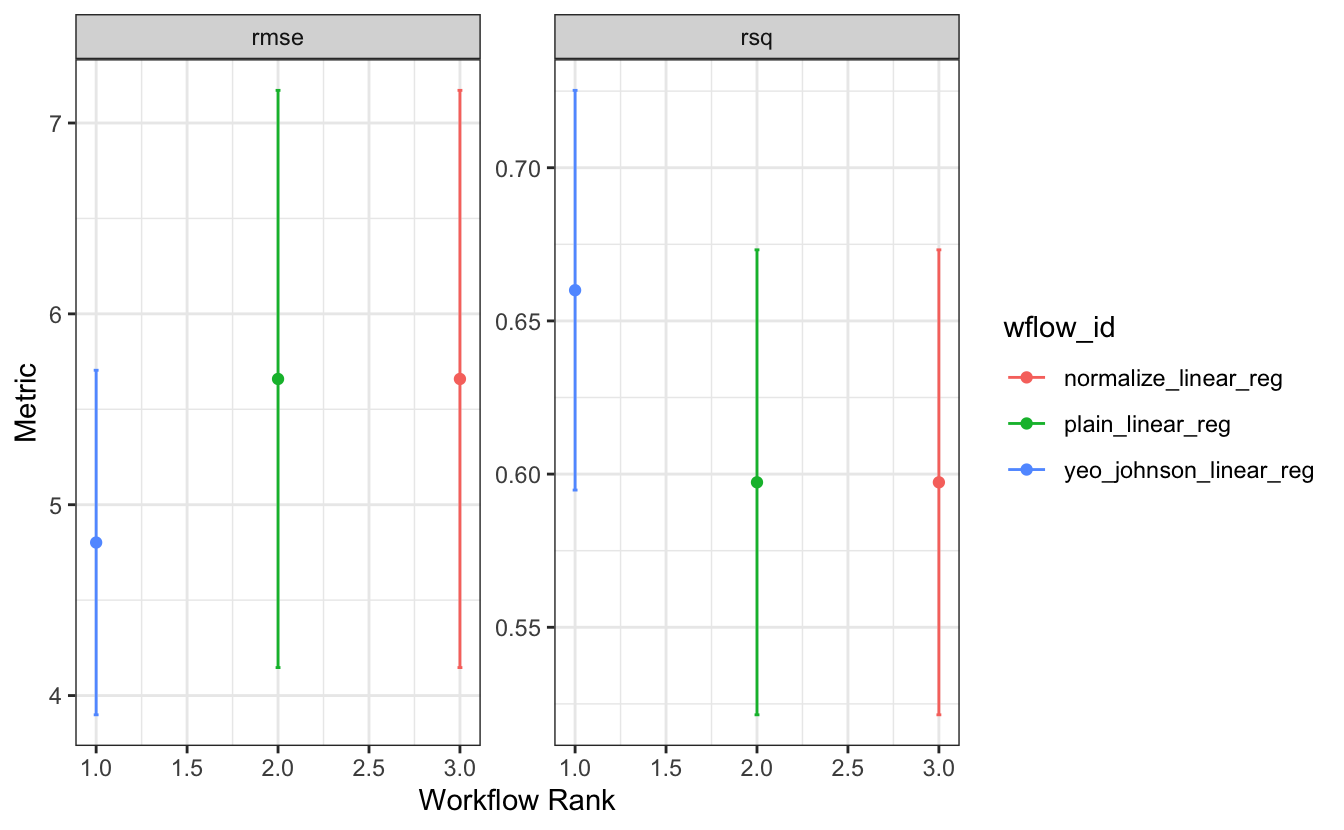
This makes it easy to spot that it’s the Yeo-Johnson transformation that makes the difference here!
Acknowledgements
We’d like to thank those in the community that contributed to tidymodels in the last quarter:
- baguette: @EmilHvitfeldt, and @topepo.
- brulee: @jrosell, and @topepo.
- butcher: @juliasilge.
- censored: @EmilHvitfeldt, @hfrick, @simonpcouch, and @tripartio.
- dials: @hfrick, and @topepo.
- embed: @EmilHvitfeldt.
- finetune: @hfrick, @jrosell, @mfansler, @simonpcouch, and @topepo.
- hardhat: @DavisVaughan, and @simonpcouch.
- modeldata: @topepo.
- parsnip: @birbritto, @EmilHvitfeldt, @hfrick, @jmunyoon, @marcelglueck, @mattheaphy, @mesdi, @nipnipj, @pgg1309, @simonpcouch, @topepo, and @wzbillings.
- probably: @brshallo, @Jeffrothschild, @jgaeb, @simonpcouch, and @topepo.
- recipes: @DemetriPananos, @EmilHvitfeldt, @jdonland, @JiahuaQu, @joranE, @mikemahoney218, @olivroy, @SantiagoD999, @simonpcouch, @stufield, and @topepo.
- rsample: @EmilHvitfeldt, @hfrick, @mikemahoney218, @paulcbauer, @StevenWallaert, @topepo, and @ZWael.
- shinymodels: @simonpcouch.
- stacks: @simonpcouch.
- tidyclust: @EmilHvitfeldt, and @katieburak.
- tidymodels: @jkylearmstrong, @mine-cetinkaya-rundel, @nikosGeography, @nipnipj, and @topepo.
- tune: @AlbertoImg, @EmilHvitfeldt, @hfrick, @joranE, @joshuagi, @lionel-, @marcozanotti, @Peter4801, @rfsaldanha, @simonpcouch, @topepo, and @walkerjameschris.
- workflows: @EmilHvitfeldt, @mesdi, @Milardkh, @simonpcouch, and @topepo.
- workflowsets: @hfrick, and @simonpcouch.
- yardstick: @asb2111, @Dpananos, @EduMinsky, @EmilHvitfeldt, @hfrick, and @tripartio.
We’re grateful for all of the tidymodels community, from observers to users to contributors. Happy modeling!