
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles.
Since the beginning of 2021, we have been publishing
quarterly updates here on the tidyverse blog summarizing what’s new in the tidymodels ecosystem. The purpose of these regular posts is to share useful new features and any updates you may have missed. You can check out the
tidymodels tag to find all tidymodels blog posts here, including our roundup posts as well as those that are more focused, like the
post on the release of the new desirability2 package.
Since our last roundup post, there have been CRAN releases of 7 tidymodels packages. Here are links to their NEWS files:
We’ll highlight a few especially notable changes below: a new package with data for modeling, nearest neighbor distance matching cross-validation for spatial data, and a website refresh.
First, loading the collection of packages:
modeldatatoo
Many of the datasets used in tidymodels examples are available in the modeldata package. The new modeldatatoo package now extends the collection by several bigger datasets. To allow for the bigger size, the package does not contain those datasets directly but rather provides functions to access them, prefixed with data_. For example:
library(modeldatatoo)
data_animals()
#> # A tibble: 610 × 48
#> text colour lifespan weight kingdom class phylum diet conservation_status
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 "Aardv… Brown… 23 years 60kg … Animal… Mamm… Chord… Omni… Least Concern
#> 2 "Abyss… Fawn,… NA NA NA NA NA NA NA
#> 3 "Adeli… Black… 10 - 20… 3kg -… Animal… Aves Chord… Carn… Least Concern
#> 4 "Affen… Black… NA NA NA NA NA NA NA
#> 5 "Afgha… Black… NA NA NA NA NA NA NA
#> 6 "Afric… Grey,… 60 - 70… 3,600… Animal… Mamm… Chord… Herb… Threatened
#> 7 "Afric… Black… 15 - 20… 1.4kg… Animal… Mamm… Chord… Omni… Least Concern
#> 8 "Afric… Brown… 8 - 15 … 25g -… Animal… Amph… Chord… Carn… Least Concern
#> 9 "Afric… Grey,… 60 - 70… 900kg… Animal… Mamm… Chord… Herb… Endangered
#> 10 "Afric… Black… 15 - 20… 1.4kg… Animal… Mamm… Chord… Omni… Least Concern
#> # ℹ 600 more rows
#> # ℹ 39 more variables: order <chr>, scientific_name <chr>, skin_type <chr>,
#> # habitat <chr>, predators <chr>, family <chr>, lifestyle <chr>,
#> # average_litter_size <chr>, genus <chr>, top_speed <chr>,
#> # favourite_food <chr>, main_prey <chr>, type <chr>, common_name <chr>,
#> # group <chr>, size <chr>, distinctive_features <chr>, size_l <chr>,
#> # origin <chr>, special_features <chr>, location <chr>, …
The new datasets are:
data_animals()contains a long-form description of the animal (in thetextcolumn) as well as quite a bit of missing data and malformed fields.data_chimiometrie_2019()contains spectra measured at 550 (unknown) wavelengths, published as the challenge at the Chimiometrie 2019 conference.data_elevators()contains information on a subset of the elevators in New York City.
Because those datasets are stored online, accessing them requires an active internet connection. We plan on using those datasets mostly for workshops and websites. The datasets in the modeldata package are part of the package directly, so they can be used everywhere (regardless of an active internet connection). We typically use them for package documentation.
spatialsample
spatialsample is a package for spatial resampling, extending the rsample framework to help create spatial extrapolation between your analysis and assessment data sets.
The latest release of spatialsample includes nearest neighbor distance matching (NNDM) cross-validation via
spatial_nndm_cv(). NNDM is a variant of leave-one-out cross-validation which assigns each observation to a single assessment fold, and then attempts to remove data from each analysis fold until the nearest neighbor distance distribution between assessment and analysis folds matches the nearest neighbor distance distribution between training data and the locations a model will be used to predict.
Proposed by Milà et al. (2022), this method aims to provide accurate estimates of how well models will perform in the locations they will actually be predicting. This method was originally implemented in the CAST package and can now be used with spatialsample as well.
Let’s use the Ames housing data and turn it from a regular tibble into a sf object for spatial data.
library(spatialsample)
data(ames, package = "modeldata")
ames_sf <- sf::st_as_sf(ames, coords = c("Longitude", "Latitude"), crs = 4326)Let’s assume that we are building a model to predict observations similar to this subset of the data:
ames_prediction_sites <- ames_sf[2001:2100, ]Let’s create NNDM cross-validation folds from a reduced training set as an example, just to keep things light.
ames_folds <- spatial_nndm_cv(ames_sf[1:100, ], ames_prediction_sites)The resulting rset contains 100 splits of the data, always keeping 1 of the 100 data points in the assessment set.
ames_folds
#> # A tibble: 100 × 2
#> splits id
#> <list> <chr>
#> 1 <split [50/1]> Fold001
#> 2 <split [83/1]> Fold002
#> 3 <split [50/1]> Fold003
#> 4 <split [50/1]> Fold004
#> 5 <split [50/1]> Fold005
#> 6 <split [50/1]> Fold006
#> 7 <split [50/1]> Fold007
#> 8 <split [76/1]> Fold008
#> 9 <split [86/1]> Fold009
#> 10 <split [88/1]> Fold010
#> # ℹ 90 more rows
Starting with all other 99 points in the analysis set, points are excluded until the distribution of nearest neighbor distances from the analysis set to the assessment set matches that of nearest neighbor distances from the training set to the prediction sites.
Looking at one of the splits, we can see the single assessment point, the points included in the analysis set, and the points excluded as the buffer.
get_rsplit(ames_folds, 3) |>
autoplot()
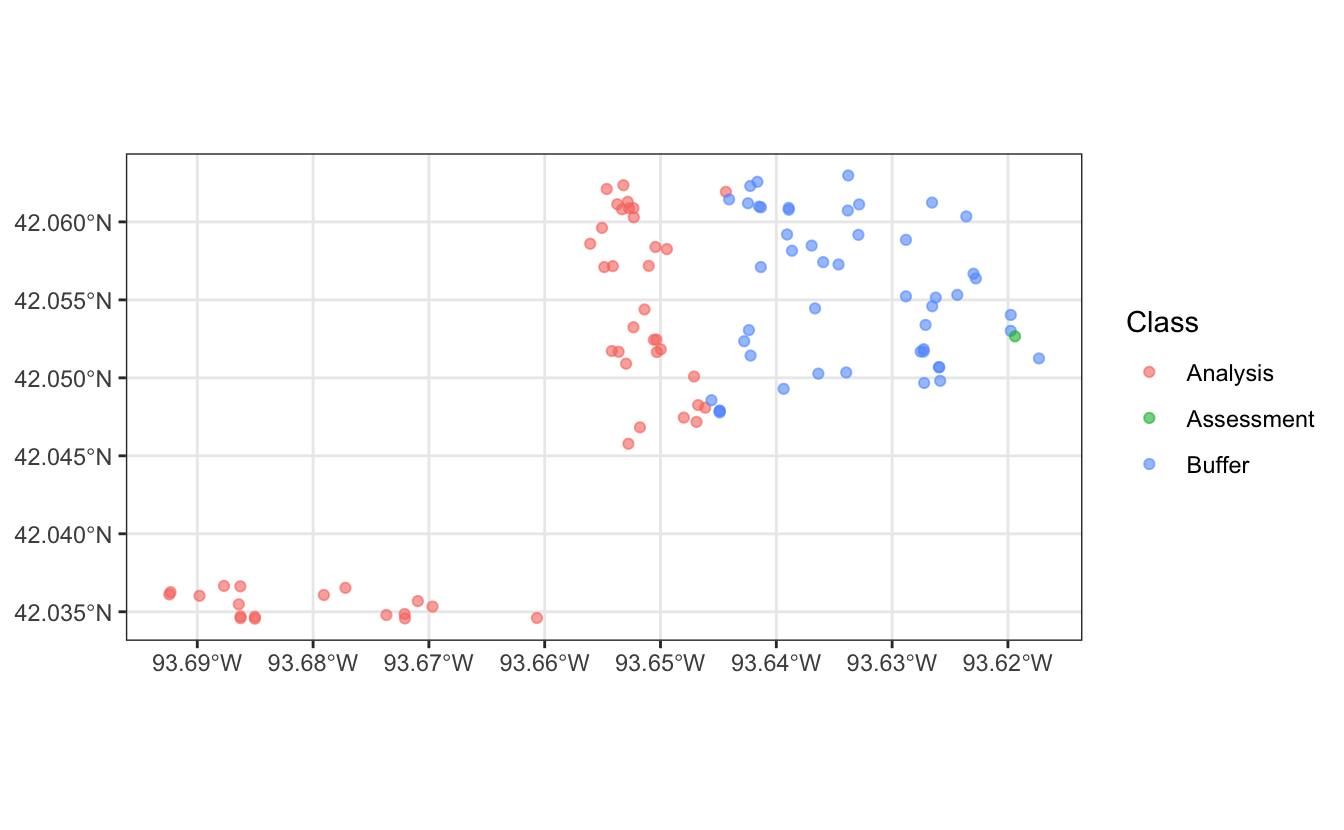
The ames_fold object can then be used with functions from the tune package as usual.
tidymodels.org
The tidymodels website, tidymodels.org, has been updated to use Quarto. Things largely look the same as before but this change simplifies the build system which should make it easier for more people to contribute.
This change to Quarto has also allowed us to improve the search functionality of the website. The tables for finding parsnip models, recipe steps, and broom tidiers at https://www.tidymodels.org/find/ now all list objects across all CRAN packages, not just tidymodels packages. This should make it much easier to find the right extension for your task, even if not implemented within tidymodels!
And if it does not exist yet, open an issue on GitHub or browse the developer documentation for extending tidymodels!
Acknowledgements
We’d like to extend our thanks to all of the contributors to tidymodels in the last quarter:
- agua: @gvelasq.
- broom: @awcm0n, @gregmacfarlane, @jwilliman, @mccarthy-m-g, @RoyalTS, @simonpcouch, and @ste-tuf.
- desirability2: @topepo.
- embed: @EmilHvitfeldt, and @naveranoc.
- probably: @agormp, @EmilHvitfeldt, @juliasilge, @simonpcouch, and @topepo.
- spatialsample: @jamesgrecian, @mikemahoney218, and @nipnipj.
- tidymodels: @forecastingEDs, @JosiahParry, and @topepo.