
The tidymodels framework is a collection of R packages for modeling and machine learning using tidyverse principles.
Since the beginning of 2021, we have been publishing
quarterly updates here on the tidyverse blog summarizing what’s new in the tidymodels ecosystem. The purpose of these regular posts is to share useful new features and any updates you may have missed. You can check out the
tidymodels tag to find all tidymodels blog posts here, including our roundup posts as well as those that are more focused, like these posts from the past couple months:
Since our last roundup post, there have been CRAN releases of 9 tidymodels packages. Here are links to their NEWS files:
We’ll highlight a few especially notable changes below: more specialized role selectors in recipes, extended support for grouped resampling in rsample, and a big speedup in parsnip. First, loading the collection of packages:
Specialized role selectors
The recipes package for preprocessing supports tidyselect-style variable selection, and includes some of its own selectors to support common modeling workflows.
To illustrate, we’ll make use of a dataset goofy_data with a number of different variable types:
str(goofy_data)
#> tibble [100 × 10] (S3: tbl_df/tbl/data.frame)
#> $ class: Factor w/ 2 levels "class_1","class_2": 1 1 2 1 2 1 1 2 2 2 ...
#> $ a : Factor w/ 7 levels "-3","-2","-1",..: 4 4 3 2 4 5 2 2 3 5 ...
#> $ b : Factor w/ 9 levels "-4","-3","-2",..: 9 5 4 3 4 7 4 2 3 6 ...
#> $ c : int [1:100] 0 0 0 0 0 0 0 -1 0 1 ...
#> $ d : int [1:100] 0 1 1 1 0 1 1 0 0 1 ...
#> $ e : int [1:100] 1 0 1 0 0 1 1 0 1 1 ...
#> $ f : num [1:100] 1.01 -1.99 2.18 2.3 -3.01 ...
#> $ g : num [1:100] -0.845 1.456 1.948 1.354 1.085 ...
#> $ h : num [1:100] -0.285 0.59 -0.938 1.447 0.424 ...
#> $ i : chr [1:100] "white" "maroon" "maroon" "maroon" ...
Imagine a classification problem on the goofy_data where we’d like to predict class using the remaining variables as predictors. The selector functions allow us to perform operations on only the predictors with a certain class. For instance, centering and scaling all numeric predictors:
recipe(class ~ ., goofy_data) %>%
step_normalize(all_numeric_predictors()) %>%
prep()
#> Recipe
#>
#> Inputs:
#>
#> role #variables
#> outcome 1
#> predictor 9
#>
#> Training data contained 100 data points and no missing data.
#>
#> Operations:
#>
#> Centering and scaling for c, d, e, f, g, h [trained]
Or making dummy variables out of each of the nominal predictors:
recipe(class ~ ., goofy_data) %>%
step_dummy(all_nominal_predictors()) %>%
prep()
#> Recipe
#>
#> Inputs:
#>
#> role #variables
#> outcome 1
#> predictor 9
#>
#> Training data contained 100 data points and no missing data.
#>
#> Operations:
#>
#> Dummy variables from a, b, i [trained]
Operations like those above have been long-standing functionality in recipes, and are powerful tools for effective modeling. The most recent release of recipes introduced finer-grain selectors for variable types. For instance, we may want to only center and scale the double (i.e. real-valued) predictors, excluding the integers. With the new release of recipes, we can easily do so:
recipe(class ~ ., goofy_data) %>%
step_normalize(all_double_predictors()) %>%
prep()
#> Recipe
#>
#> Inputs:
#>
#> role #variables
#> outcome 1
#> predictor 9
#>
#> Training data contained 100 data points and no missing data.
#>
#> Operations:
#>
#> Centering and scaling for f, g, h [trained]
This is one of a number of new selectors:
The
all_nominal()selector now has finer-grained versionsall_string(),all_factor(),all_unordered(), andall_ordered().The
all_numeric()selector now has finer-grained versionsall_double(), andall_integer().New
all_logical(),all_date(), andall_datetime()selectors.
All new selectors have *_predictors() variants. You can read more about recipes 1.0.3 in the
release notes.
Grouped resampling
The most recent release of rsample introduced support for stratification with grouped resampling. Consider the following toy data set on the number of melons in a household:
melons
#> # A tibble: 4,928 × 3
#> household n_melons chops
#> <fct> <int> <chr>
#> 1 1 114 Yes
#> 2 1 179 Yes
#> 3 1 163 Yes
#> 4 1 35 Yes
#> 5 1 93 Yes
#> 6 1 55 Yes
#> 7 1 165 Yes
#> 8 1 30 Yes
#> 9 1 140 Yes
#> 10 1 7 Yes
#> # … with 4,918 more rows
There are 100 different households in this dataset. Each member of the household has some number of melons n_melons in their fridge. A household, i.e., all its members, either chops their melons or keeps them whole.
Each of the resampling functions in rsample have a group_*ed analogue. From rsample’s
“Common Patterns” article:
Often, some observations in your data will be “more related” to each other than would be probable under random chance, for instance because they represent repeated measurements of the same subject or were all collected at a single location. In these situations, you often want to assign all related observations to either the analysis or assessment fold as a group, to avoid having assessment data that's closely related to the data used to fit a model.
For example, the grouped initial_split() variant will allot the training and testing set mutually exclusive levels of the group variable:
resample <- group_initial_split(melons, group = household)
sum(
unique(training(resample)$household) %in%
unique(testing(resample)$household)
)
#> [1] 0
However, note that there are only a few households that don’t chop their melons, and those households tend to have many more melons to chop!
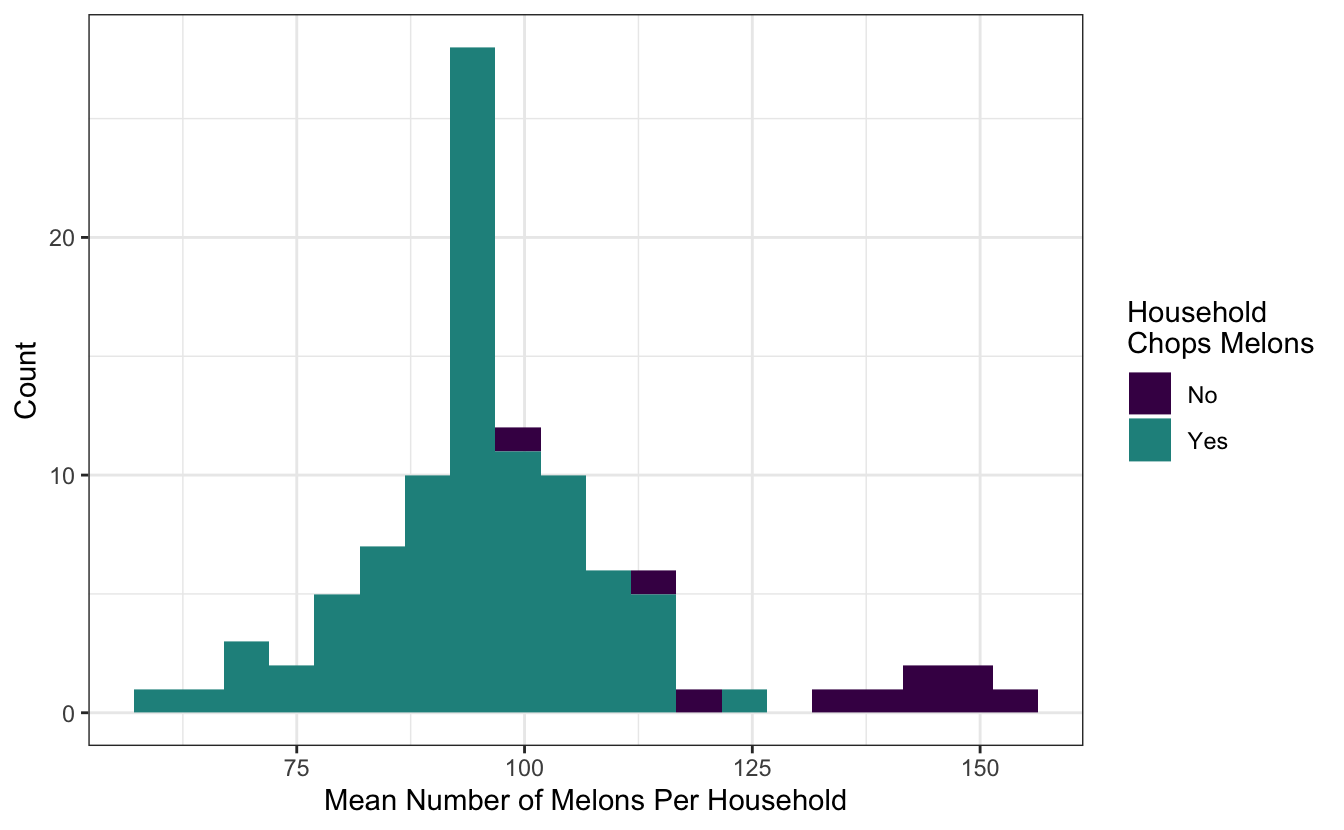
If we’re ultimately interested in modeling whether a household chops their melons, we ought to ensure that both values of chops are well-represented in both the training and testing set. The argument strata = chops indicates that sampling by household will occur within values of chops. Note that the strata must be constant in each group, so here, all members of a household need to either chop or not.
resample_stratified <- group_initial_split(melons, group = household, strata = chops)Note that this resampling scheme still resulted in different households being allotted to training and testing:
sum(
unique(training(resample_stratified)$household) %in%
unique(testing(resample_stratified)$household)
)
#> [1] 0
Also, though, it ensured that similar proportions of chops values are allotted to the training and testing set:
diff(c(
mean(training(resample_stratified)$chops == "Yes"),
mean(testing(resample_stratified)$chops == "Yes")
))
#> [1] 0.01000042
You can read more about rsample 1.1.1 in the release notes.
Performance speedup
We recently made a performance tweak, released as part of parsnip 1.0.3, that resulted in a substantial speedup in fit time. Fitting models via parsnip is a fundamental operation in the tidymodels, so the speedup can be observed across many modeling workflows.
The figure below demonstrates this speedup in an experiment involving fitting a simple linear regression model on resamples of simulated data. Simulated datasets with between one hundred and one million rows were partitioned into five, ten, or twenty folds and fitted with the new version of parsnip as well as the version preceding it. With smaller datasets, the speedup is negligible, but fit times decrease by a factor of three to five once training data reaches one million rows.
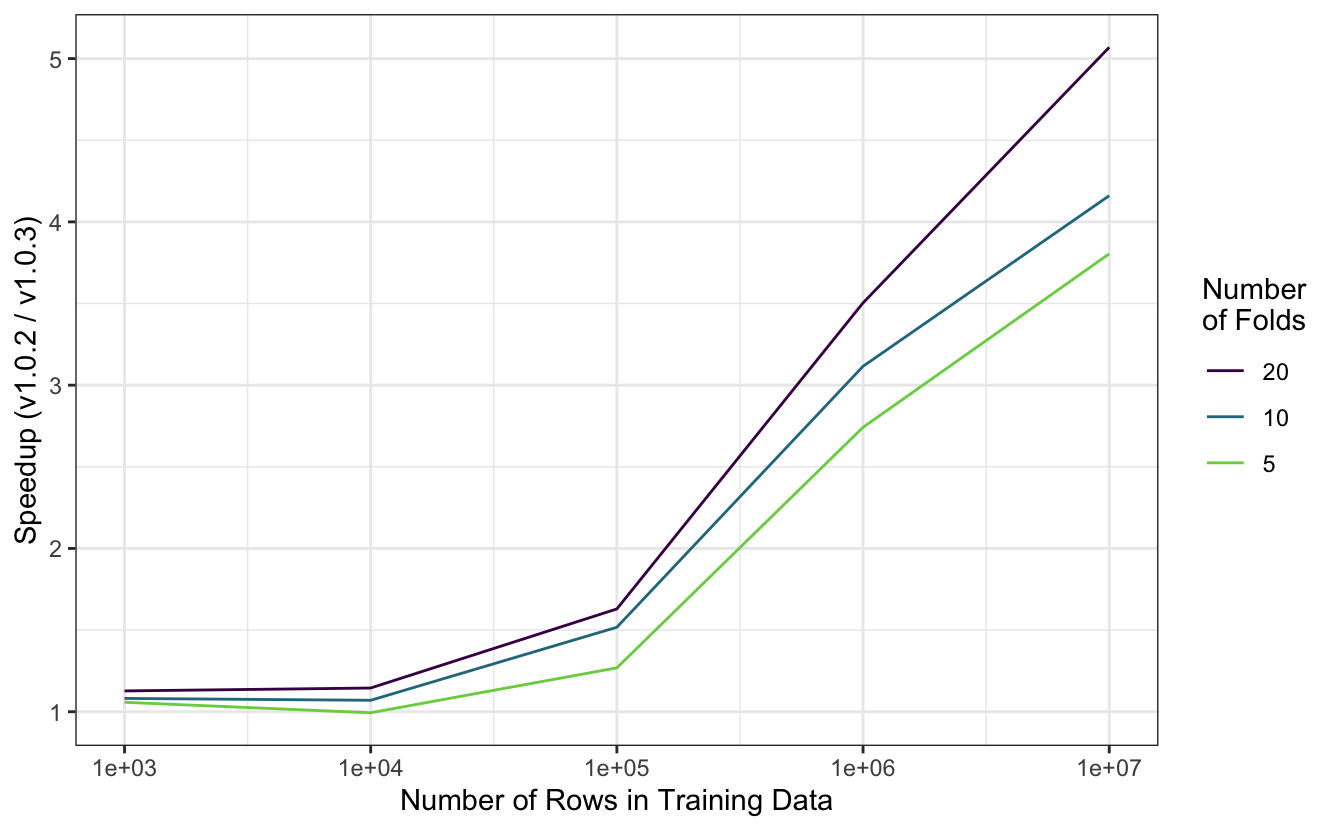
You can read more about parsnip 1.0.3 in the release notes.
Acknowledgements
We’d like to thank those in the community that contributed to tidymodels in the last quarter:
- bonsai: @HenrikBengtsson, and @simonpcouch.
- broom: @amorris28, @capnrefsmmat, @larmarange, @lukepilling, and @simonpcouch.
- butcher: @galen-ft, and @juliasilge.
- dials: @EmilHvitfeldt, @hfrick, and @Tadge-Analytics.
- parsnip: @EmilHvitfeldt, @exsell-jc, @fkohrt, @hfrick, @jonthegeek, @Marwolaeth, @mattwarkentin, @schoonees, @simonpcouch, @sweiner123, and @topepo.
- recipes: @andeek, @DavisVaughan, @EmilHvitfeldt, @hfrick, @joeycouse, @mdancho84, and @mobius-eng.
- rsample: @bschneidr, @DavisVaughan, @EmilHvitfeldt, @hfrick, @mikemahoney218, @pgg1309, and @topepo.
- stacks: @simonpcouch.
- workflows: @EmilHvitfeldt, @hfrick, @simonpcouch, @talegari, and @xiaochi-liu.
We’re grateful for all of the tidymodels community, from observers to users to contributors, and wish you all a happy new year!