
We’re extremely pleased to announce the first release of censored on CRAN. The censored package is a parsnip extension package for survival models.
You can install it from CRAN with:
install.packages("censored")This blog post will introduce a new model type, a new mode, and new prediction types for survival analysis in the tidymodels framework. We have previously blogged about these changes while they were in development, now they have been released!
Model types, modes, and engines
A parsnip model specification consists of three elements:
- a model type such as linear model, random forest, support vector machine, etc
- a computational engine such as a specific R package or tools outside of R like Keras or Stan
- a mode such as regression or classification
parsnip 1.0.0 introduces a new mode "censored regression" and the censored package provides engines to fit various models in this new mode. With the addition of the new
proportional_hazards() model type, the available models cover parametric, semi-parametric, and tree-based models:
| model | engine |
|---|---|
bag_tree() | rpart |
boost_tree() | mboost |
decision_tree() | rpart |
decision_tree() | partykit |
proportional_hazards() | survival |
proportional_hazards() | glmnet |
rand_forest() | partykit |
survival_reg() | survival |
survival_reg() | flexsurv |
All models can be fitted through a formula interface. For example, when the engine allows for stratification variables, these can be specified by using a
strata() term in the formula, as in the survival package.
The cetaceans data set contains information about dolphins and whales living in captivity in the USA. It is derived from a
Tidy Tuesday data set and you can install the corresponding data package with pak::pak("hfrick/cetaceans").
library(cetaceans)
str(cetaceans)
#> tibble [1,358 × 10] (S3: tbl_df/tbl/data.frame)
#> $ age : num [1:1358] 28 44 39 38 38 37 36 36 35 34 ...
#> $ event : num [1:1358] 0 0 0 0 0 0 0 0 0 0 ...
#> $ species : chr [1:1358] "Bottlenose" "Bottlenose" "Bottlenose" "Bottlenose" ...
#> $ sex : chr [1:1358] "F" "F" "M" "F" ...
#> $ birth_decade : num [1:1358] 1980 1970 1970 1970 1970 1980 1980 1980 1980 1980 ...
#> $ born_in_captivity: logi [1:1358] TRUE TRUE TRUE TRUE TRUE TRUE ...
#> $ time_in_captivity: num [1:1358] 1 1 1 1 1 1 1 1 1 1 ...
#> $ origin_location : chr [1:1358] "Marineland Florida" "Dolphin Research Center" "SeaWorld" "SeaWorld" ...
#> $ transfers : int [1:1358] 0 0 13 1 2 2 2 2 3 4 ...
#> $ current_location : chr [1:1358] "Marineland Florida" "Dolphin Research Center" "SeaWorld" "SeaWorld" ...To illustrate the new modelling function
proportional_hazards() and the formula interface for glmnet, let’s fit a penalized Cox model.
cox_penalized <- proportional_hazards(penalty = 0.1) %>%
set_engine("glmnet") %>%
set_mode("censored regression") %>%
fit(
Surv(age, event) ~ sex + transfers + strata(born_in_captivity),
data = cetaceans
)Prediction types
For censored regression, parsnip now also includes new prediction types:
"time"for the survival time"survival"for the survival probability"hazard"for the hazard"quantile"for quantiles of the event time distribution"linear_pred"for the linear predictor
Predictions made with censored respect the tidymodels principles of:
- The predictions are always inside a tibble.
- The column names and types are unsurprising and predictable.
- The number of rows in
new_dataand the output are the same.
Let’s demonstrate that with a small data set to predict on: just three observations, and the first one includes a missing value for one of the predictors.
cetaceans_3 <- cetaceans[1:3,]
cetaceans_3$sex[1] <- NAPredictions of types "time" and "survival" are available for all model/engine combinations in censored.
predict(cox_penalized, new_data = cetaceans_3, type = "time")
#> # A tibble: 3 × 1
#> .pred_time
#> <dbl>
#> 1 NA
#> 2 31.8
#> 3 52.6Survival probability can be predicted at multiple time points, specified through the time argument to
predict(). Here we are predicting survival probability at age 10, 20, 30, and 40 years.
pred <- predict(cox_penalized, new_data = cetaceans_3, type = "survival", time = c(10, 20, 30, 40))
pred
#> # A tibble: 3 × 1
#> .pred
#> <list>
#> 1 <tibble [4 × 2]>
#> 2 <tibble [4 × 2]>
#> 3 <tibble [4 × 2]>The .pred column is a list-column, containing nested tibbles:
# for the observation with NA
pred$.pred[[1]]
#> # A tibble: 4 × 2
#> .time .pred_survival
#> <dbl> <dbl>
#> 1 10 NA
#> 2 20 NA
#> 3 30 NA
#> 4 40 NA
# without NA
pred$.pred[[2]]
#> # A tibble: 4 × 2
#> .time .pred_survival
#> <dbl> <dbl>
#> 1 10 0.729
#> 2 20 0.567
#> 3 30 0.386
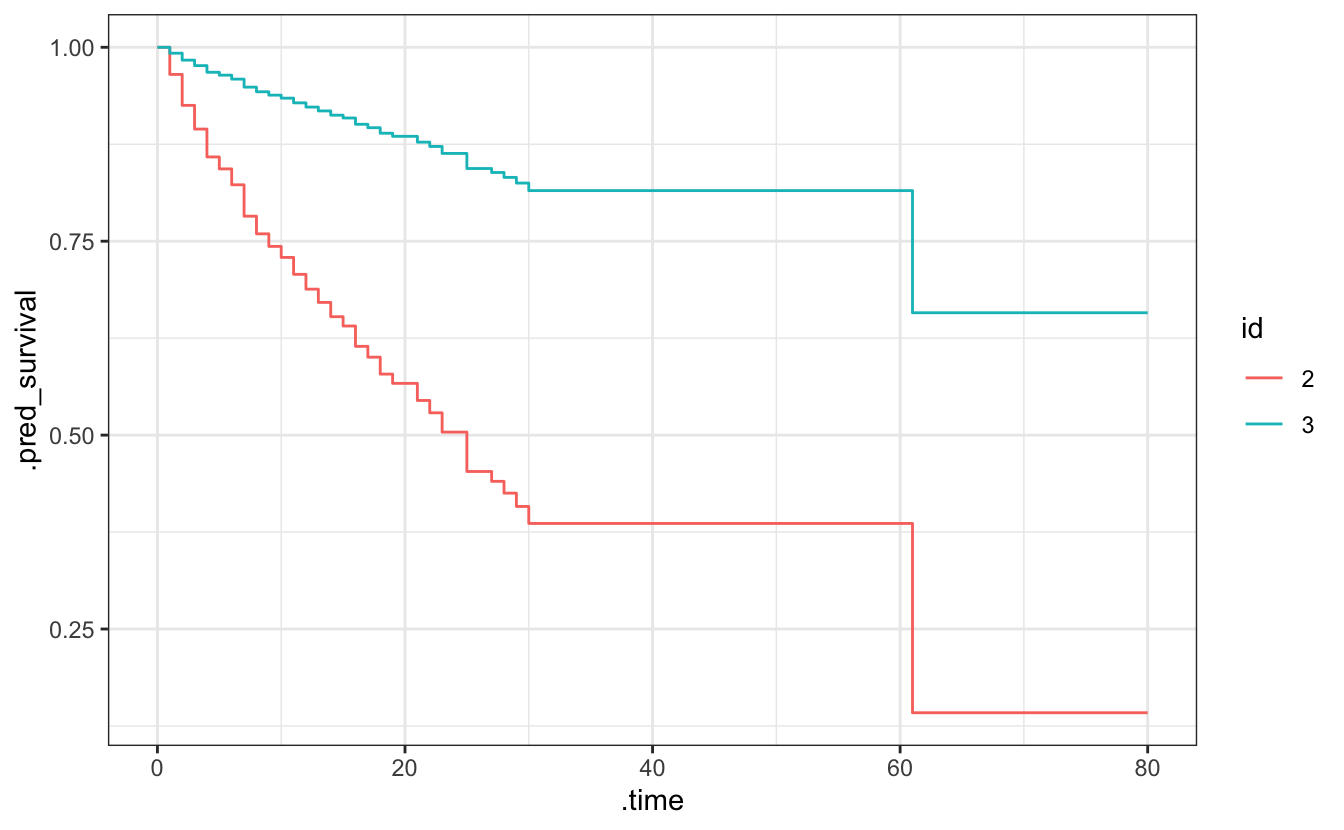
#> 4 40 0.386This can be used to visualize an approximation of the underlying survival curve.
library(ggplot2)
predict(cox_penalized, new_data = cetaceans[2:3,],
type = "survival", time = seq(0, 80, 1)) %>%
dplyr::mutate(id = factor(2:3)) %>%
tidyr::unnest(cols = .pred) %>%
ggplot(aes(x = .time, y = .pred_survival, col = id)) +
geom_step() +
theme_bw()
More examples of available models, engines, and prediction types can be found in the article Fitting and Predicting with censored.
What’s next?
Our aim is to broadly integrate survival analysis in the tidymodels framework. Next, we’ll be working on adding appropriate metrics to the yardstick package and enabling model tuning via the tune package.
Acknowledgements
A big thanks to all the contributors: @bcjaeger, @brunocarlin, @caimiao0714, @DavisVaughan, @dvdsb, @EmilHvitfeldt, @erikvona, @gvelasq, @hfrick, @jennybc, @mattwarkentin, @mikemahoney218, @schelhorn, and @topepo.