
The new release of tune is chock full of improvements and new features. This blog post is the second of three posts exploring the updates available in tune 0.1.2. When combined with the latest releases of hardhat and parsnip, one upgrade that tidymodels users can now use in their day-to-day modeling work is some support for sparse data structures during fitting and tuning.
Why sparse data?
In some subject matter domains, it is common to have lots and lots of zeroes after transforming data to a representation appropriate for analysis or modeling. Text data is one such example. The small_fine_foods dataset of Amazon reviews of fine foods contains a column review that we as humans can read and understand.
library(tidyverse)
library(tidymodels)
data("small_fine_foods")
training_data
## # A tibble: 4,000 x 3
## product review score
## <chr> <chr> <fct>
## 1 B000J0LSBG "this stuff is not stuffing its not good at all save your… other
## 2 B000EYLDYE "I absolutely LOVE this dried fruit. LOVE IT. Whenever I ha… great
## 3 B0026LIO9A "GREAT DEAL, CONVENIENT TOO. Much cheaper than WalMart and I… great
## 4 B00473P8SK "Great flavor, we go through a ton of this sauce! I discovere… great
## 5 B001SAWTNM "This is excellent salsa/hot sauce, but you can get it for $2… great
## 6 B000FAG90U "Again, this is the best dogfood out there. One suggestion: … great
## 7 B006BXTCEK "The box I received was filled with teas, hot chocolates, and… other
## 8 B002GWH5OY "This is delicious coffee which compares favorably with much … great
## 9 B003R0MFYY "Don't let these little tiny cans fool you. They pack a lot … great
## 10 B001EO5ZXI "One of the nicest, smoothest cup of chai I've made. Nice mix… great
## # … with 3,990 more rows
Computers, on the other hand, need that review variable to be heavily preprocessed and transformed in order for it to be ready for most modeling. We typically need to
tokenize the text, find word frequencies, and perhaps
compute tf-idf. There are quite a number of different structures we can use to store the results of this preprocessing. We can keep the results in a long, tidy tibble, which is excellent for exploratory data analysis.
library(tidytext)
tidy_reviews <- training_data %>%
unnest_tokens(word, review) %>%
count(product, word) %>%
bind_tf_idf(word, product, n)
tidy_reviews
## # A tibble: 208,306 x 6
## product word n tf idf tf_idf
## <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 B0000691JF and 1 0.1 0.234 0.0234
## 2 B0000691JF i 1 0.1 0.262 0.0262
## 3 B0000691JF in 1 0.1 0.654 0.0654
## 4 B0000691JF just 1 0.1 1.54 0.154
## 5 B0000691JF manner 1 0.1 5.52 0.552
## 6 B0000691JF ordered 1 0.1 2.76 0.276
## 7 B0000691JF prompt 1 0.1 5.81 0.581
## 8 B0000691JF the 1 0.1 0.206 0.0206
## 9 B0000691JF usual 1 0.1 5.04 0.504
## 10 B0000691JF what 1 0.1 2.27 0.227
## # … with 208,296 more rows
We can also transform these results to a wide format, often a good fit when the next step is a modeling or machine learning algorithm.
wide_reviews <- tidy_reviews %>%
select(product, word, tf_idf) %>%
pivot_wider(names_from = word, names_prefix = "word_",
values_from = tf_idf, values_fill = 0)
wide_reviews
## # A tibble: 4,000 x 13,797
## product word_and word_i word_in word_just word_manner word_ordered word_prompt
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 B00006… 0.0234 0.0262 0.0654 0.154 0.552 0.276 0.581
## 2 B00008… 0.00780 0 0 0 0 0 0
## 3 B00008… 0.00177 0.00397 0.0198 0.0117 0 0 0
## 4 B00008… 0.00582 0.00489 0.00813 0 0 0 0
## 5 B00008… 0.00246 0.0166 0.0207 0.0162 0 0 0
## 6 B00008… 0.00334 0.00750 0.00935 0 0 0 0
## 7 B00008… 0.0114 0.00729 0.00909 0 0 0 0
## 8 B00008… 0.00768 0.0129 0 0 0 0 0
## 9 B00008… 0.00976 0 0 0 0 0 0
## 10 B00008… 0.0156 0 0 0 0 0 0
## 11 B00008… 0.00404 0.0181 0 0 0 0 0
## 12 B00008… 0.0142 0.00397 0 0 0 0 0
## 13 B00008… 0.0160 0.00596 0.0149 0.0351 0 0 0
## 14 B00009… 0.00439 0.00656 0.00818 0 0 0 0
## 15 B0000A… 0.00679 0.00380 0.0379 0 0 0.0401 0
## # … with 3,985 more rows, and 13,789 more variables: word_the <dbl>,
## # word_usual <dbl>, word_what <dbl>, word_a <dbl>, word_anymore <dbl>,
## # word_chocolate <dbl>, word_coat <dbl>, word_dogfood <dbl>, word_ears <dbl>,
## # word_fine <dbl>, word_for <dbl>, word_great <dbl>, word_hardly <dbl>,
## # word_he <dbl>, word_health <dbl>, word_his <dbl>, word_hot <dbl>,
## # word_is <dbl>, word_itching <dbl>, word_lab <dbl>, …
Lots of zeroes! Instead of using a tibble, we can transform these results to a sparse matrix, a specialized data structure that keeps track of only the non-zero elements instead of every element.
sparse_reviews <- tidy_reviews %>%
cast_dfm(product, word, tf_idf)
sparse_reviews
## Document-feature matrix of: 4,000 documents, 13,796 features (99.6% sparse).
As is typical for text data, this document-feature matrix is extremely sparse, with many zeroes. Most documents do not contain most words. By using this kind of specialized structure instead of anything like a vanilla matrix or data.frame, we secure two benefits:
- We can taken advantage of the speed gained from any specialized model algorithms built for sparse data.
- The amount of memory this object requires decreases dramatically.
How big of a change in memory are we talking about?
lobstr::obj_sizes(wide_reviews, sparse_reviews)
## * 443,539,792 B
## * 3,581,200 B
A blueprint for sparse models
Before the most recent releases of hardhat, parsnip, and tune, there was no support for sparse data structures within tidymodels. Now, you can specify a hardhat blueprint for sparse data.
library(hardhat)
sparse_bp <- default_recipe_blueprint(composition = "dgCMatrix")
The dgCMatrix composition is from the
Matrix package, and is the most standard class for sparse numeric matrices in modeling in R. (You can also specify a dense matrix composition with composition = "matrix".)
Workflows and sparsity
The blueprint is used under the hood by the hardhat functions to process data. To get ready to fit our model using the sparse blueprint, we can set up our preprocessing recipe:
library(textrecipes)
text_rec <-
recipe(score ~ review, data = training_data) %>%
step_tokenize(review) %>%
step_stopwords(review) %>%
step_tokenfilter(review, max_tokens = 1e3) %>%
step_tfidf(review)
And we set up our model as we would normally:
lasso_spec <-
logistic_reg(penalty = 0.02, mixture = 1) %>%
set_engine("glmnet")
The regularized modeling of the glmnet package is an example of an algorithm that has specialized approaches for sparse data. If we pass in dense data with set_engine("glmnet"), the underlying model will take one approach, but it will use a different, faster approach especially built for sparse data if we pass in a sparse matrix. Typically, we would recommend centering and scaling predictors using step_normalize() before fitting a regularized model like glmnet. However, if we do this, we would no longer have all our zeroes and sparse data. Instead, we can “normalize” these text predictors using tf-idf so that they are all on the same scale.
Let’s put together two workflows, one using the sparse blueprint and one using the default behavior.
wf_sparse <-
workflow() %>%
add_recipe(text_rec, blueprint = sparse_bp) %>%
add_model(lasso_spec)
wf_default <-
workflow() %>%
add_recipe(text_rec) %>%
add_model(lasso_spec)
Comparing model results
Now let’s use fit_resamples() to estimate how well this model fits with both options and measure performance for both.
set.seed(123)
food_folds <- vfold_cv(training_data, v = 3)
results <- bench::mark(
iterations = 10, check = FALSE,
sparse = fit_resamples(wf_sparse, food_folds),
default = fit_resamples(wf_default, food_folds),
)
results
## # A tibble: 2 x 6
## expression min median `itr/sec` mem_alloc `gc/sec`
## <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
## 1 sparse 7.78s 7.87s 0.127 788MB 0.127
## 2 default 1.19m 1.2m 0.0139 870MB 0.0139
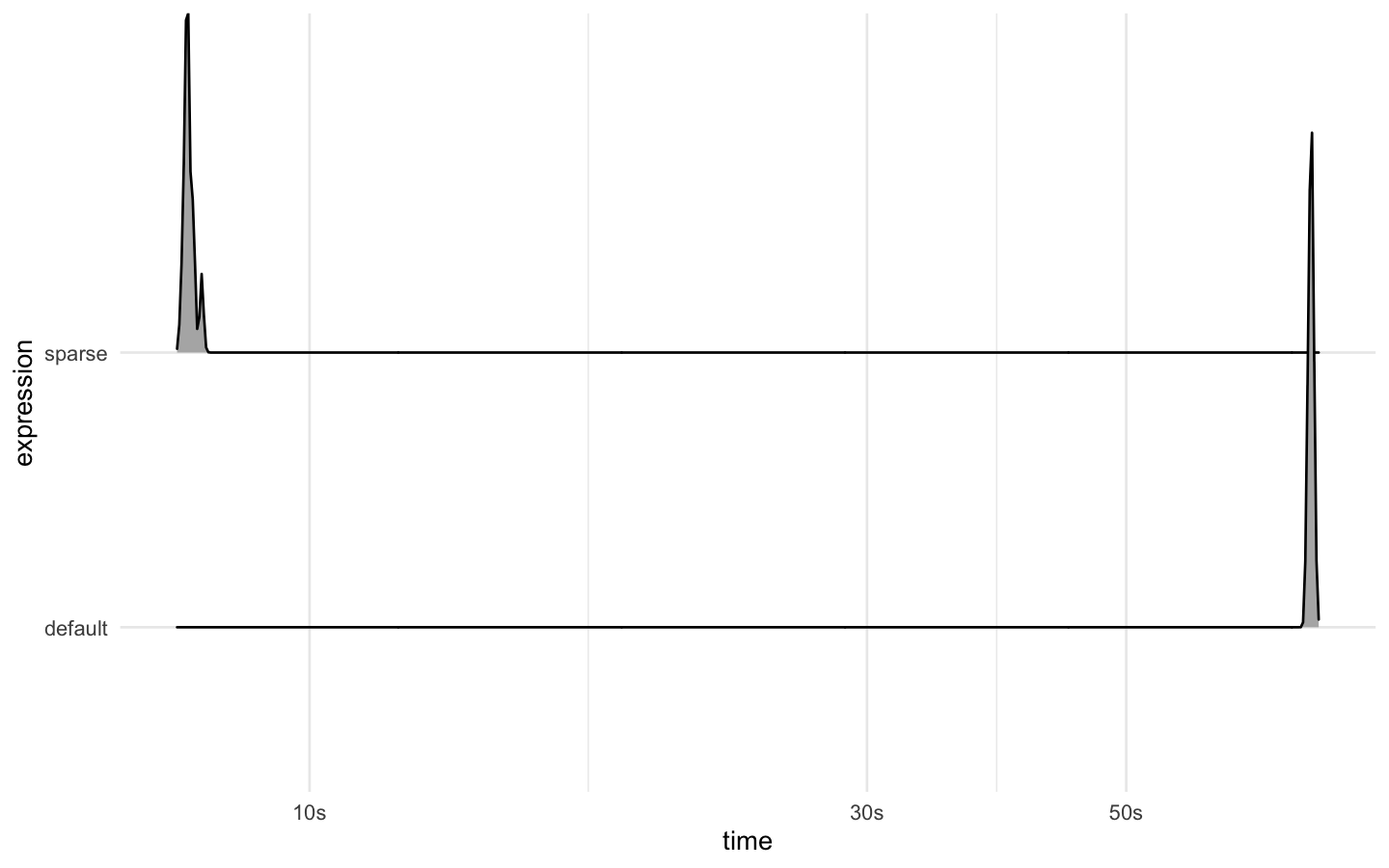
We see on the order of a 10x speed gain by using the sparse blueprint!
autoplot(results, type = "ridge")
The model performance metrics are the same:
fit_resamples(wf_sparse, food_folds) %>%
collect_metrics()
## # A tibble: 2 x 5
## .metric .estimator mean n std_err
## <chr> <chr> <dbl> <int> <dbl>
## 1 accuracy binary 0.715 3 0.00399
## 2 roc_auc binary 0.797 3 0.00598
fit_resamples(wf_default, food_folds) %>%
collect_metrics()
## # A tibble: 2 x 5
## .metric .estimator mean n std_err
## <chr> <chr> <dbl> <int> <dbl>
## 1 accuracy binary 0.715 3 0.00399
## 2 roc_auc binary 0.797 3 0.00598
To see a detailed text modeling example using this dataset of food reviews, without sparse encodings but complete with tuning hyperparameters, check out
our article on tidymodels.org.
Current limits
In tidymodels, the support for sparse data structures begins coming out of a
preprocessing recipe and continues throughout the fitting and tuning process. We typically still expect the input into a recipe to be a data frame, as shown in this text analysis example, and there is very limited support within tidymodels for starting with a sparse matrix, for example by using parsnip::fit_xy().
There are currently three models in parsnip that support a sparse data encoding:
- the glmnet engine for linear and logistic regression (including multinomial regression),
- the XGBoost engine for boosted trees, and
- the ranger engine for random forests.
There is heterogeneity in how recipes themselves handle data internally; this is why we didn’t see a huge decrease in memory use when comparing wf_sparse to wf_default. The
textrecipes package internally adopts the idea of a
tokenlist, which is memory efficient for sparse data, but other recipe steps may handle data in a dense tibble structure. Keep these current limits in mind as you consider the memory requirements of your modeling projects!